¿Qué son los LLMs?
Los LLMs (Large Language Models) son modelos de inteligencia artificial entrenados con grandes volúmenes de datos para comprender y generar lenguaje natural. Se basan en la arquitectura Transformer, introducida en el paper «Attention Is All You Need» de 2017, que revolucionó el procesamiento del lenguaje natural (NLP).
Estos modelos, como GPT-4, Llama 2, Cohere Command R+, pueden realizar tareas avanzadas de texto, como:
✅ Resumir información
✅ Responder preguntas con razonamiento avanzado
✅ Generar contenido
✅ Analizar documentos
✅ Asistir en programación y depuración de código
¿Cómo funcionan?
Los LLMs utilizan aprendizaje profundo y se entrenan en billones de palabras para predecir secuencias de texto de manera eficiente. Sin embargo, pueden mejorarse aún más con fine-tuning (ajuste de modelos) o mediante técnicas como RAG (Retrieval-Augmented Generation), que combinan generación con búsqueda en bases de datos o documentos.

📈 Impacto en Empresas e Instituciones
Los LLMs han transformado múltiples sectores, desde atención al cliente hasta automatización de procesos complejos. Su adopción ha crecido en grandes empresas tecnológicas, startups e instituciones gubernamentales.
🔹 Empresas: Automatización e Innovación
- Atención al cliente: Chatbots inteligentes y asistentes virtuales que ofrecen respuestas rápidas y personalizadas. Ejemplo: Chatbots de bancos, e-commerce y seguros.
- Generación de contenido: Creación automática de reportes, descripciones de productos y marketing personalizado.
- Soporte técnico y desarrollo de software: LLMs como GitHub Copilot ayudan a programadores con sugerencias de código y depuración.
- Análisis de datos y generación de insights: Empresas financieras y de salud los utilizan para analizar tendencias y detectar anomalías en datos.
🏛️ Instituciones: Eficiencia y Accesibilidad
- Educación: Tutores virtuales, resúmenes automáticos de libros y generación de material de aprendizaje interactivo.
- Gobierno: Asistentes automatizados para responder consultas ciudadanas y mejorar la gestión documental.
- Salud: Modelos que analizan historiales médicos y ayudan a interpretar estudios clínicos.
- Legal y cumplimiento: Revisión de documentos legales y contratos, mejorando la eficiencia de abogados y analistas.
💡 Ejemplo real: Empresas como Google y Microsoft han integrado LLMs en productos como Bard y Copilot, mientras que hospitales usan modelos de IA para mejorar diagnósticos.
Recomendamos la lectura de Los modelos de Lenguaje Grande (LLMs) y su impacto en las Iniciativas de Calidad de Datos en Linkedin.
🚀 ¿Por qué aprender sobre LLMs ahora?
El auge de la IA generativa está redefiniendo cómo interactuamos con la información. Comprender y aplicar LLMs no solo te dará ventaja competitiva, sino que abrirá nuevas oportunidades en tecnología, negocios y ciencia de datos.
💭 Ahora que tienes esta base, avancemos con el mini-roadmap para aprender cómo trabajar con estos modelos y desarrollar aplicaciones basadas en IA.
1. Fundamentos de LLMs (Large Language Models)
Objetivo: Comprender cómo funcionan los LLMs, su arquitectura y cómo interactúan con los datos.
Conceptos clave:
- Transformers: Entender la arquitectura básica de los transformers (Self-attention, Encoder-Decoder).
- Pre-entrenamiento y Fine-tuning: Diferencia entre modelos preentrenados (como GPT, Llama) y cómo se afinan para tareas específicas.
- Modelos de generación: Diferencia entre modelos de causalidad (generación de texto) y modelos de clasificación (pregunta-respuesta).
Herramientas/Recursos:
- Transformers de Hugging Face – Guía oficial.
- Paper de Attention Is All You Need (base del transformer).
- Cursos:
2. Programación en Python (para IA)
Objetivo: Aprender a programar con Python para manejar datos, integrar modelos y procesar información.
Conceptos clave:
- Manipulación de datos: Usar pandas y numpy para manejar datos.
- Manejo de APIs: Cómo interactuar con APIs de modelos (Hugging Face, OpenAI, etc.).
- Integración de bases de datos: Uso de SQLite, PostgreSQL, ElasticSearch desde Python.
Un ejemplo para usar pipeline para generar texto con el modelo "CohereForAI/aya-expanse-8b" de Cohere, debes hacer algo como esto:
import { CohereClientV2 } from "cohere-ai";
const client = new CohereClientV2({ token: "<YOUR_API_KEY>" });
await client.chatStream(
{
model: "command-a-03-2025",
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hola, háblame de tus capacidades"
}
]
},
temperature: 0.3
}
)
Obtendremos una respuesta similar a esta:
¡Hola! Soy Command, un modelo de lenguaje avanzado creado por Cohere. Estoy diseñado para ayudar a los usuarios de manera eficiente y precisa. Aquí te presento algunas de mis capacidades principales:
Generación de texto: Puedo generar texto coherente y relevante en respuesta a una amplia variedad de preguntas y temas. Puedo escribir ensayos, historias, correos electrónicos, resúmenes y más.
Respuestas a preguntas: Estoy capacitado para responder preguntas sobre una amplia gama de temas, desde ciencia y historia hasta cultura pop y entretenimiento. Puedo proporcionar información detallada y precisa, así como fuentes confiables cuando sea necesario.
Traducción: Puedo traducir texto entre múltiples idiomas, lo que me permite ayudar a usuarios de todo el mundo.
Resumen de texto: Puedo resumir artículos, libros y otros documentos largos en un formato conciso y fácil de entender.
Conversación: Estoy diseñado para mantener conversaciones naturales y fluidas con los usuarios. Puedo entender el contexto y responder de manera apropiada, lo que me permite mantener una conversación significativa.
Personalización: Puedo adaptarme a las necesidades y preferencias individuales de los usuarios. Puedo ajustar mi estilo de escritura, tono y nivel de detalle para satisfacer las necesidades específicas de cada usuario.
Análisis de sentimientos: Puedo analizar el sentimiento de un texto y determinar si es positivo, negativo o neutral. Esto me permite ayudar a los usuarios a comprender la opinión pública sobre un tema o producto.
Generación de ideas: Puedo ayudar a los usuarios a generar ideas creativas y soluciones innovadoras para problemas complejos.
Corrección gramatical y ortográfica: Puedo corregir errores gramaticales y ortográficos en el texto, lo que me permite ayudar a los usuarios a mejorar su escritura.
Aprendizaje continuo: Estoy constantemente aprendiendo y mejorando a través de la retroalimentación de los usuarios y la actualización de mis conocimientos con la información más reciente.
Esas son solo algunas de mis capacidades. ¿Hay algo específico en lo que pueda ayudarte hoy? ¡No dudes en pedirme lo que necesites!Recuerda que las plataformas de LLMs ofrecen un Playground donde puedes generar y probar tus scripts previo a implementarlos.
3. Ingeniería de Prompt
Objetivo: Aprender a diseñar prompts eficientes y a estructurar la interacción con los modelos para obtener las respuestas más precisas.
Conceptos clave:
- Plantillas de Prompt: Uso de plantillas básicas como
"INST","USER","SYSTEM"para interacción. - Chain-of-Thought (CoT): Técnicas para hacer que el modelo razone paso a paso.
- Instrucciones y contexto: Cómo dar contexto suficiente y directo para generar respuestas relevantes.
Anthropic ofrece una variada Biblioteca de Prompts que puedes consultare libremente.

Herramientas/Recursos:
- Prompt Engineering: Hugging Face Course – Prompt Engineering
- Improving LLM performance with Chain-of-Thought
- OpenAI Cookbook – Ejemplos prácticos.
4. LangChain y Agentes
Objetivo: Usar LangChain para estructurar flujos más complejos de interacción con modelos de lenguaje.
LangChain implementa una interfaz estándar para modelos de lenguaje grandes y tecnologías relacionadas, como modelos de incrustación y almacenes de vectores, y se integra con cientos de proveedores. Consulte la página de integraciones para obtener más información.
Si en cambio quieres ejecutar un flujo de conversación con mensajes en formato role-content, necesitarás usar un modelo compatible con chat en transformers, como ChatGPT, Llama, Mistral, etc. Para eso, puedes usar AutoModelForCausalLM y AutoTokenizer con un enfoque más personalizado.
Los modelos compatibles con chat suelen usar plantillas de formato de mensajes, que estructuran la conversación en una cadena de texto antes de enviarla al modelo. Estas plantillas varían según el modelo y determinan cómo se interpretan los roles como "user", "assistant" o "system".
Por ejemplo, modelos como Llama 2, Mistral, y Command R utilizan estructuras específicas. Veamos algunos ejemplos.
Ejemplo con Llama 2
Llama 2 usa una plantilla tipo:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"}
]
formatted_prompt = (
"[INST] " + messages[1]["content"] + " [/INST]"
)
inputs = tokenizer(formatted_prompt, return_tensors="pt")
output = model.generate(**inputs, max_length=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))Aquí, Llama 2 usa "[INST]" y "[/INST]" para marcar instrucciones del usuario.
Ejemplo con Mistral (como Mixtral)
Mistral usa un formato similar:
formatted_prompt = (
"<s>[INST] " + messages[1]["content"] + " [/INST]</s>"
)Ejemplo con Cohere Command R
Cohere Command R (Command R+, Command R Plus) usa una estructura más flexible, pero generalmente requiere formatear los mensajes en texto plano o JSON antes de enviarlos.
import { CohereClientV2 } from "cohere-ai";
const client = new CohereClientV2({ token: "<YOUR_API_KEY>" });
await client.chatStream({
model: "command-r",
messages: [
{
role: "user",
content: [{ type: "text", text: "Hola, háblame de tus capacidades" }],
},
],
temperature: 0.3,
});
Conceptos clave:
- Flujos de trabajo (chains): Conectar pasos del modelo para hacer tareas más complejas.
- Memoria: Mantener información de interacciones pasadas (chatbots persistentes).
- Agentes: Usar herramientas externas (como APIs de búsqueda, bases de datos) para enriquecer la interacción.
Herramientas/Recursos:
- LangChain Docs – Documentación oficial.
- LangChain Examples – Ejemplos prácticos.
- Cursos de LangChain: LangChain Academy.
5. Bases de Datos: SQL y ElasticSearch
Objetivo: Dominar SQL y ElasticSearch para realizar consultas eficientes y recuperar datos relevantes.
Conceptos clave:
- SQL: Consultas, joins, subconsultas, índices y optimización de rendimiento.
- ElasticSearch: Consultas de texto completo, búsqueda por relevancia, uso de embeddings y búsqueda vectorial.

Herramientas/Recursos:
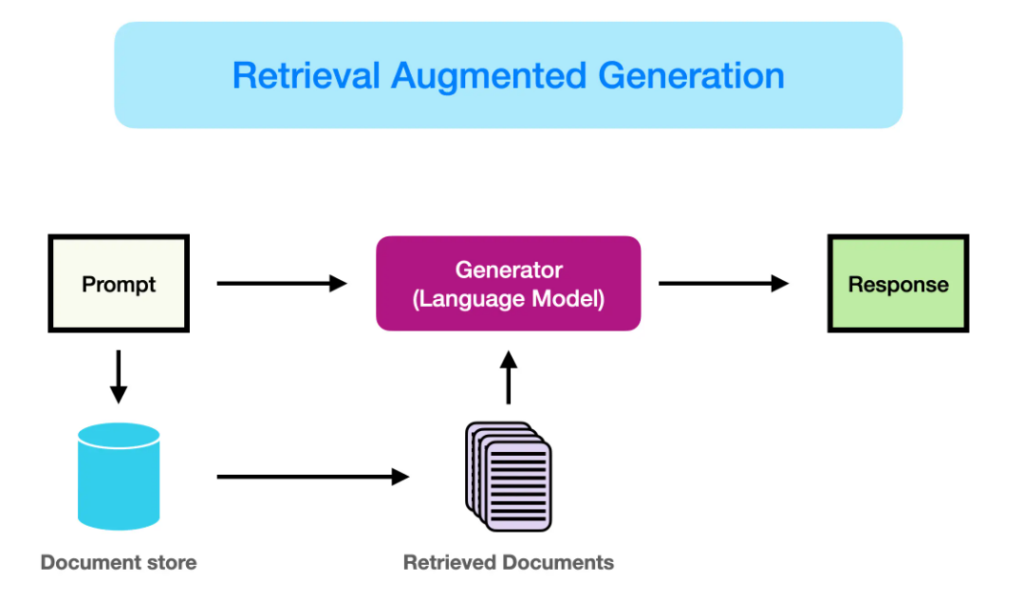
6. RAG (Retrieval-Augmented Generation)
Objetivo: Crear sistemas RAG que combinen la recuperación de datos con la generación de texto para respuestas más precisas.
Conceptos clave:
- Embeddings y búsqueda semántica: Usar modelos de embeddings (por ejemplo,
sentence-transformers) para buscar información relevante de manera eficiente. - Pipeline RAG: Integración de recuperación + generación.
- Performance y optimización: Cómo mejorar la latencia y el costo en un sistema RAG.
Herramientas/Recursos:
7. Integración y Proyecto Final
Objetivo: Integrar todo lo aprendido en un solo proyecto, como un asistente inteligente o un sistema de preguntas y respuestas que recupere datos de una base de datos.
Pasos recomendados:
- Estructura un proyecto con LangChain.
- Agrega memoria y conexión a bases de datos.
- Implementa un modelo LLM como backend para la generación.
- Prueba con datos reales y ajusta el flujo de trabajo.
 Save as PDF
Save as PDF