
Antes de implementar soluciones de escalado, es crucial tener en mente un principio fundamental:
Evita la optimización prematura o escalar tu base de datos antes de que sea realmente necesario.
El escalado introduce complejidades como un desarrollo de funcionalidades más lento, un aumento en la complejidad del sistema, pruebas más difíciles y una resolución de errores más desafiante.
Acepta estas contrapartidas solo si tu aplicación ha alcanzado su capacidad máxima.
Mantén tu sistema simple y escala únicamente cuando sea genuinamente necesario.
Con esto en mente, veamos 4 de las principales estrategias de escalado.
Si bien no todos los ingenieros necesitan dominar las cuatro estrategias que se presentan a continuación, el conocimiento de estos conceptos nos equipa para construir sistemas robustos y escalables cuando la necesidad surge.
1) Almacenamiento en Caché de Consultas a la Base de Datos
El almacenamiento en caché de las consultas a la base de datos es una de las mejoras más sencillas que puedes implementar para manejar la carga de la base de datos.
Reduce la carga almacenando en caché los resultados de las consultas solicitadas con frecuencia. Herramientas como Redis o Memcached almacenan estos resultados en memoria, lo que permite que tu aplicación obtenga datos más rápido sin acceder repetidamente a la base de datos.

Ejemplo:
Imagina una aplicación que muestra el perfil de un usuario. Esta información no cambia con frecuencia. En lugar de consultar la base de datos cada vez que alguien visita un perfil, puedes almacenar el resultado de la consulta en caché.
# Ejemplo conceptual usando Redis con Python
import redis
r = redis.Redis(host='localhost', port=6379, db=0)
def obtener_perfil_usuario(user_id):
clave_cache = f"perfil:{user_id}"
datos_cache = r.get(clave_cache)
if datos_cache:
print(f"Obteniendo perfil de {user_id} desde caché")
return datos_cache.decode('utf-8')
else:
# Simulación de consulta a la base de datos
datos_db = f"Datos del perfil del usuario {user_id} desde la DB"
r.setex(clave_cache, 3600, datos_db) # Guardar en caché por 1 hora
print(f"Obteniendo perfil de {user_id} desde la DB y guardando en caché")
return datos_db
print(obtener_perfil_usuario(123))
print(obtener_perfil_usuario(123)) # La segunda vez se obtiene de la caché2) Índices de la Base de Datos
Otra estrategia directa que ofrece beneficios de rendimiento significativos.
La indexación acelera la recuperación de datos al permitir la localización rápida de la información sin escanear cada fila. Típicamente implementados con árboles B, los índices reducen la complejidad temporal del acceso a los datos de O(n) a O(logn). Esto resulta en consultas significativamente más rápidas.
Ejemplo:
Considera una tabla de usuarios con millones de registros. Si a menudo buscas usuarios por su dirección de correo electrónico, agregar un índice a la columna email permitirá que la base de datos encuentre los registros mucho más rápido que si tuviera que revisar cada fila.
Expresión SQL:
-- Creación de un índice en la columna 'email' de la tabla 'users'
CREATE INDEX idx_email ON users (email);
¿Qué tipos de indices podemos usar en sistemas de bases de datos como SQL Server, Postgres y MySQL?
Cada uno de estos sistemas de gestión de bases de datos relacionales (RDBMS) ofrece varios tipos de índices optimizados para diferentes casos de uso. Aquí te presento los tipos de índices más comunes en SQL Server, PostgreSQL y MySQL:
SQL Server
SQL Server ofrece varios tipos de índices:
Clustered Index:
- Determina el orden físico de los datos en la tabla. Solo puede haber un índice clustered por tabla.
- Las hojas del índice clustered son las filas de datos en sí.
- Si no se define un índice clustered, la tabla se almacena como un “heap” (montículo) sin un orden específico.
- Generalmente se crea automáticamente al definir una Primary Key si no existe un índice clustered.
-- Ejemplo de creación de un índice clustered
CREATE CLUSTERED INDEX IX_ProductModel_Name
ON Production.ProductModel (Name);Non-Clustered Index:
- Es un índice separado de las filas de datos. Contiene una estructura de árbol con la clave de índice y un puntero a la fila de datos.
- Una tabla puede tener múltiples índices non-clustered.
- Se utilizan para acelerar las consultas que filtran o ordenan por columnas que no son la clave clustered.
-- Ejemplo de creación de un índice non-clustered
CREATE NONCLUSTERED INDEX IX_Product_Name
ON Production.Product (Name);Unique Index:
- Garantiza que los valores en las columnas indexadas sean únicos.
- Puede ser clustered o non-clustered.
- Se crea automáticamente al definir una restricción
UNIQUE.
-- Ejemplo de creación de un índice unique non-clustered
CREATE UNIQUE NONCLUSTERED INDEX IX_Email
ON dbo.Users (Email);Full-Text Index:
- Optimizado para búsquedas de texto completo en columnas de tipo carácter.
- Permite búsquedas por palabras, frases, o utilizando operadores booleanos.
-- Ejemplo de creación de un índice full-text
CREATE FULLTEXT INDEX ON Production.ProductDescription (Description)
KEY INDEX PK_ProductDescription_ProductDescriptionID
WITH STOPLIST = SYSTEM;Columnstore Index:
- Almacena los datos por columnas en lugar de por filas.
- Optimizado para cargas de trabajo de almacenamiento de datos (data warehousing) y consultas analíticas que involucran agregaciones sobre grandes conjuntos de datos.
- Puede ser clustered o non-clustered.
Filtered Index:
- Un índice non-clustered optimizado para consultas que seleccionan una pequeña porción de los datos de una tabla.
- Utiliza una cláusula
WHEREpara indexar solo un subconjunto de las filas.
XML Index:
- Optimizado para consultar datos almacenados en tipo de datos XML.
- Soporta índices primarios y secundarios sobre columnas XML.
Spatial Index:
- Optimizado para consultar datos espaciales (tipos de datos geometry y geography).
Hash Index:
- Solo disponible para tablas en memoria optimizadas.
- Altamente optimizado para búsquedas de igualdad.
PostgreSQL
PostgreSQL ofrece una variedad de tipos de índices, permitiendo elegir el más adecuado para cada necesidad:
B-tree:
- Es el tipo de índice predeterminado.
- Funciona bien para la mayoría de las consultas, incluyendo búsquedas de igualdad y rangos (
<,<=,=,>=,>). - También se puede usar para ordenar.
-- Ejemplo de creación de un índice B-tree
CREATE INDEX idx_users_email ON users (email);Hash:
- Útil solo para búsquedas de igualdad (
=). - No está basado en un árbol, sino en una tabla hash.
- A partir de PostgreSQL 10, son seguros para WAL (Write-Ahead Logging).
-- Ejemplo de creación de un índice Hash
CREATE INDEX idx_users_name_hash ON users USING HASH (name);GIN (Generalized Inverted Index):
- Optimizado para datos que contienen múltiples valores (como arrays, documentos JSONB) y para búsquedas de texto completo.
- Permite buscar valores que aparecen dentro de los elementos indexados.
-- Ejemplo de creación de un índice GIN para un array
CREATE INDEX idx_tags_gin ON articles USING GIN (tags);
-- Ejemplo de creación de un índice GIN para texto completo
CREATE INDEX idx_articles_fts ON articles USING GIN (to_tsvector('english', body));GiST (Generalized Search Tree):
- Soporta una amplia variedad de estrategias de búsqueda, incluyendo operadores geométricos, de texto completo y de vecinos más cercanos.
- Es más genérico que B-tree y GIN.
-- Ejemplo de creación de un índice GiST para datos geométricos
CREATE INDEX idx_locations_gist ON places USING GIST (location);SP-GiST (Space-Partitioned GiST):
- Una forma de índice GiST que es particularmente útil para datos jerárquicos, como árboles de cuadratura.BRIN (Block Range Index):
- Optimizado para tablas muy grandes donde las columnas indexadas tienen una correlación natural con su ubicación física en el disco (por ejemplo, columnas de fecha en orden cronológico).
- Almacena un resumen de los valores dentro de rangos de bloques de páginas.
-- Ejemplo de creación de un índice BRIN en una columna de fecha
CREATE INDEX idx_events_date_brin ON events USING BRIN (event_date);MySQL
MySQL también ofrece varios tipos de índices:
B-tree:
- Es el tipo de índice más común y predeterminado en la mayoría de los motores de almacenamiento (como InnoDB y MyISAM).
- Eficiente para búsquedas de igualdad, rangos y ordenación.
- Puede ser utilizado para búsquedas basadas en prefijos para columnas de tipo cadena.
-- Ejemplo de creación de un índice B-tree
CREATE INDEX idx_emails ON users (email);Hash:
- Solo disponible para el motor de almacenamiento MEMORY.
- Muy rápido para búsquedas de igualdad exactas.
- No soporta búsquedas de rango ni ordenación.
-- Ejemplo de creación de un índice Hash (solo en tablas MEMORY)
CREATE INDEX idx_lookup USING HASH (code) USING HASH;FULLTEXT:
- Diseñado para búsquedas de texto completo en columnas de tipo
TEXToVARCHAR. - Soporta búsquedas en lenguaje natural y booleanas.
-- Ejemplo de creación de un índice FULLTEXT
CREATE FULLTEXT INDEX idx_body ON articles (body);SPATIAL:
- Utilizado para indexar datos espaciales (tipos de datos
GEOMETRY,POINT, etc.). - Permite realizar consultas espaciales eficientes.
- Requiere que la tabla utilice el motor de almacenamiento MyISAM o InnoDB (para algunas versiones y tipos de datos espaciales).
-- Ejemplo de creación de un índice SPATIAL
CREATE SPATIAL INDEX idx_location ON places (location);Prefijo Indexes:
- Permiten indexar solo los primeros caracteres de una columna de tipo
BLOB,TEXT,VARCHAR, etc. - Útil para reducir el tamaño del índice.
-- Ejemplo de creación de un índice de prefijo en una columna VARCHAR
CREATE INDEX idx_name_prefix ON users (name(10)); -- Indexa los primeros 10 caracteresEs importante elegir el tipo de índice adecuado según los patrones de consulta y el tipo de datos para optimizar el rendimiento de tu base de datos.
3) Sharding de la Base de Datos
Mientras que las estrategias anteriores se centran en manejar la carga de lectura, el sharding se enfoca tanto en lecturas como en escrituras.
El sharding implica dividir tu base de datos en partes más pequeñas e independientes (shards), donde cada una maneja un subconjunto de los datos. Esto permite un escalado horizontal al distribuir la carga entre múltiples servidores. Si bien es potente, el sharding añade una complejidad significativa a la gestión de datos y la lógica de las consultas.
Típicamente, es una estrategia que solo querrás considerar después de agotar otras soluciones más simples.

4) Replicación de Lectura de la Base de Datos
En entornos con mucha carga de lectura, la replicación puede ser la siguiente mejor opción.
Con la replicación de lectura, tienes una única base de datos a la que escribes. Esta se clona en varias bases de datos réplica (tantas como necesites) de las que lees. Cada base de datos réplica reside en una máquina diferente.
Analogía: Imagina un libro original del que se hacen múltiples copias. El escritor solo modifica el original, pero muchos lectores pueden leer simultáneamente de sus propias copias.
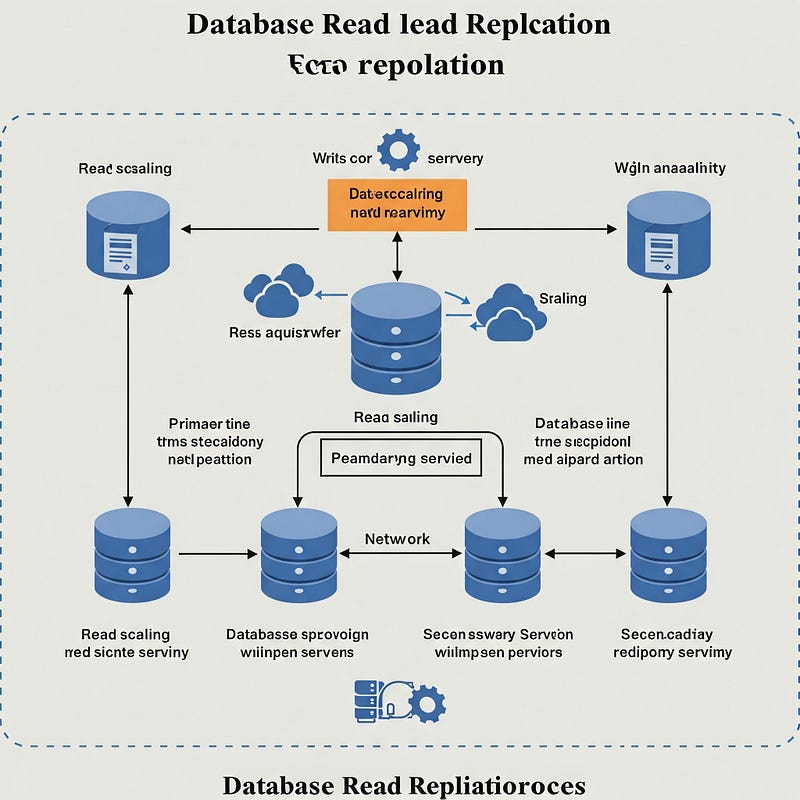
Si bien estas son algunas de las estrategias de escalado de bases de datos más populares, existen muchas otras, incluyendo el particionamiento, el pooling de conexiones y más.
Rercomendamos la lectura de:
- Escalado vertical frente a escalado horizontal
- ¿Qué es la partición de bases de datos?
- ¿Qué es Data Replication?