
La narrativa dominante hoy es: “cómo la IA mejora la seguridad” pero mucho menos se habla de: 👉 “cómo la IA cambia el modelo de ataque”
En la medida en que los modelos de lenguaje (LLMs) se integran en aplicaciones reales —APIs, agentes, automatizaciones— también emerge una nueva superficie de ataque. Lo que antes era un backend tradicional, hoy es un endpoint de inferencia, y eso cambia las reglas del juego.
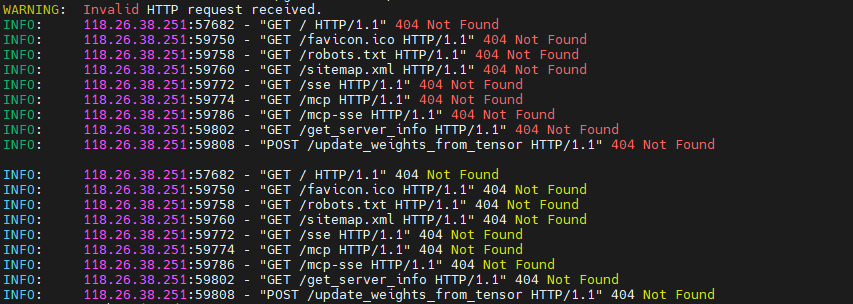
Un escenario cada vez más común es el siguiente: despliegas tu servicio de inferencia (por ejemplo, con un runtime como Ollama o similar), revisas los logs… y comienzas a ver solicitudes extrañas:
GET /sse
GET /mcp
GET /mcp-sse
GET /get_server_info
POST /update_weights_from_tensorA primera vista podrían parecer simples bots. Pero no son los típicos crawlers de buscadores. Aquí hay algo más.
Reconocimiento automático: el primer paso del ataque
Estos accesos forman parte de una fase inicial conocida como reconocimiento automatizado. Bots especializados recorren direcciones IP públicas buscando:
- endpoints conocidos de inferencia
- rutas comunes en frameworks de IA
- servicios mal configurados o expuestos
El objetivo no es atacar de inmediato, sino clasificar objetivos:
- “interesante”
- “no interesante”
Este proceso sigue un patrón claro:
🔹 scan → 🔹 fingerprint → 🔹 exploit (si es posible)¿Qué buscan realmente estos bots?
A diferencia del escaneo tradicional (puertos abiertos, CMS vulnerables), estos bots están diseñados para detectar infraestructura de IA. Algunos ejemplos:
/sse→ streaming de tokens/mcp→ implementaciones del Model Context Protocol/generateo/chat→ endpoints de inferencia- endpoints de actualización de modelos o pesos
El objetivo puede ser:
- uso no autorizado del modelo (abuso de recursos)
- extracción de información (prompt leakage)
- ejecución de prompts maliciosos (prompt injection)
- identificación de vulnerabilidades para ataques posteriores
El riesgo real: no es el escaneo, es lo que sigue
El escaneo por sí solo no es el problema. El riesgo aparece cuando:
- el endpoint no tiene autenticación
- no hay control de concurrencia
- no existe rate limiting
- se exponen rutas internas o experimentales
En esos casos, el sistema puede pasar rápidamente de “no interesante” a “objetivo explotable”.

Nuevas superficies de ataque en sistemas LLM
Los sistemas de inferencia introducen vectores que los equipos tradicionales de seguridad no siempre contemplan:
- Prompt Injection: manipulación de instrucciones del modelo
- Data Exfiltration: fuga de contexto o datos sensibles
- Model Abuse: uso del modelo como recurso computacional gratuito
- Endpoint Enumeration: descubrimiento de capacidades internas
Esto obliga a replantear la seguridad más allá de HTTP y autenticación básica.
Medidas básicas de protección
Para cualquier backend de inferencia, estas son medidas mínimas recomendadas:
🔐 Autenticación
- API keys obligatorias
- validación estricta en cada request
⚙️ Control de carga
- colas de procesamiento
- límites de concurrencia
🚦 Rate limiting
- por IP
- por API key
🌐 Reverse proxy
- uso de Nginx o similar
- filtrado de tráfico
- ocultamiento de backend
🔍 Logging y monitoreo
- registro detallado de requests
- análisis de patrones sospechosos
🔒 Minimización de superficie
- no exponer endpoints innecesarios
- evitar rutas de debugging en producción
Cómo afrontan esto las grandes empresas
Organizaciones como OpenAI, Google o Anthropic operan con arquitecturas que incluyen:
- gateways de inferencia con control centralizado
- sistemas de detección de abuso en tiempo real
- sandboxing de prompts y respuestas
- aislamiento de contexto
- monitoreo continuo con equipos SOC especializados
Pero más allá de la infraestructura, hay un factor clave:
La comprensión del nuevo modelo de amenaza

El rol crítico de los equipos SOC
Los equipos de seguridad (SOC) deben adaptarse a esta nueva realidad.
Ya no basta con detectar:
- escaneo de puertos
- intentos de login
Ahora deben identificar:
- patrones de acceso a endpoints de inferencia
- comportamiento anómalo en prompts
- uso indebido de modelos
- exploración de capacidades del sistema
❗ Un endpoint de inferencia es ahora un activo crítico.
Y como tal, requiere visibilidad, monitoreo y defensa activa.
Conclusión
En la era generativa, exponer un modelo no es solo una decisión técnica, es una decisión de seguridad.
El simple hecho de ver solicitudes “extrañas” en los logs no debe ignorarse. Es, muchas veces, la primera señal de que tu sistema ya forma parte del mapa de exploración de bots especializados.
“Si está en Internet, ya está siendo escaneado.
Si es un endpoint de inferencia, probablemente está siendo evaluado.”
La buena noticia es que, con arquitectura adecuada y conciencia de estos riesgos, es posible construir sistemas robustos, eficientes y seguros.
El primer paso es entender que la superficie de ataque ha cambiado.
Y actuar en consecuencia.
La seguridad de endpoints (dispositivos finales) protege laptops, servidores y móviles contra ciberataques. Los tipos principales incluyen EPP (protección preventiva), EDR (detección y respuesta proactiva), XDR (visibilidad extendida), antivirus/antimalware de última generación, y soluciones basadas en la nube. Estas herramientas suelen integrarse para bloquear ransomware, ataques sin archivos y gestionar el acceso a la red.
 Save as PDF
Save as PDF

