La animación realista de rostros que hablan con imágenes, audio y movimiento 3D es un campo emocionante dentro de la inteligencia artificial y la informática gráfica. PyTorch y TorchVision son herramientas poderosas que se pueden utilizar para crear este tipo de animaciones. A continuación, te proporcionaré una visión general de los aspectos técnicos que involucra este procedimiento de creación de elementos multimedia:

- Adquisición de datos: Para crear una animación realista de un rostro que hable, primero necesitas datos de entrada. Esto puede incluir imágenes faciales, grabaciones de audio y modelos 3D de caras como se muestra en la imagen superior. Puedes obtener imágenes faciales de diversas fuentes, como conjuntos de datos públicos o capturar tus propias imágenes. Para el audio, necesitarás grabaciones de la persona cuyo rostro deseas animar o bien crear archivos de audio derivados de textos específicos, para lo cual te recomendamos seguir este tutorial. Los modelos 3D de caras también se pueden obtener a través de escaneo 3D o mediante técnicas de modelado 3D.
- Segmentación y extracción de características: Utiliza TorchVision o herramientas similares para segmentar y extraer las características clave de las imágenes faciales. Esto puede incluir la detección de puntos de referencia faciales, la identificación de expresiones faciales y la segmentación de la región de la boca.
- Procesamiento de audio: Utiliza herramientas de procesamiento de audio como PyDub o librosa para preprocesar y analizar el audio. Debes ser capaz de extraer la información de habla del audio, como los fonemas, la entonación y la duración de las palabras.
- Sincronización de audio y video: Para lograr una animación realista, es fundamental sincronizar el audio con el movimiento facial. Puedes usar algoritmos de sincronización, como Dynamic Time Warping (DTW), para lograr una correspondencia precisa entre el audio y las expresiones faciales.
- Generación de animación facial 3D: Utiliza modelos 3D de caras para generar la animación facial en 3D. PyTorch es útil para construir modelos de redes neuronales que puedan generar animaciones realistas basadas en los datos de entrada. Puedes utilizar modelos generativos adversarios (GAN) u otros tipos de modelos de redes neuronales para lograr esto. Las redes adversariales generativas son el enfoque de modelado generativo para las técnicas de aprendizaje profundo.
- Renderización 3D: Utiliza bibliotecas de renderización 3D como OpenGL o PyOpenGL para representar y renderizar la animación 3D en tiempo real. Esto incluye aplicar texturas y materiales al modelo 3D de la cara y animarla de acuerdo con las expresiones faciales y el audio.
- Integración de audio y video: Combina el audio procesado con la animación facial generada para crear una secuencia de video coherente. Puedes usar bibliotecas como OpenCV o MoviePy para lograr esto.
- Posprocesamiento y refinamiento: A menudo, se requiere posprocesamiento para mejorar la calidad de la animación. Esto puede incluir suavizado de transiciones, corrección de imperfecciones en la animación facial y ajustes finos en la sincronización audiovisual.
- Visualización y exportación: Finalmente, visualiza la animación en tiempo real o exporta el resultado en el formato deseado, como video o animación interactiva.
Ten en cuenta que estos son proyectos bastante complejo que combinan múltiples disciplinas, incluyendo visión por computadora, procesamiento de audio, aprendizaje profundo y gráficos 3D, y requieren de muchos recursos en términos de procesamiento de datos (CPU, GPU, RAM y memoria en disco). Requiere un conocimiento sólido de Python, PyTorch, y herramientas relacionadas, así como acceso a recursos de hardware potentes para el entrenamiento y la generación de modelos de animación facial realista.
Existen modelos de Inteligencia Artificial ya entrenados como SadTalker que generan coeficientes de movimiento 3D (pose de la cabeza, expresión) del 3DMM a partir de audio y modula implícitamente un novedoso renderizado de rostros con reconocimiento 3D para la generación de «rostros parlantes» (Talking Heads).
Los creadores de SatTalker lo definen así:
Para conocer los coeficientes de movimiento realistas, modelamos explícitamente las conexiones entre el audio y los diferentes tipos de coeficientes de movimiento individualmente. Precisamente, Presentamos ExpNet para aprender la expresión facial precisa a partir del audio destilando tanto coeficientes como rostros renderizados en 3D. En cuanto a la postura de la cabeza, diseñamos PoseVAE mediante un VAE condicional para sintetizar el movimiento de la cabeza en diferentes estilos. Finalmente, los coeficientes de movimiento 3D generados se asignan al espacio de puntos clave 3D no supervisados del renderizado facial propuesto y se sintetiza el vídeo final. Realizamos extensos experimentos para demostrar la superioridad de nuestro método en términos de calidad de movimiento y video.
https://arxiv.org/abs/2211.12194
Para comprender el funcionamiento de este modelo, debes seguir las instrucciones detalladas en su repositorio de GitHub para instalarlo en plataformas Windows, Linux o Mac.
En Linux debes instalar Anaconda, Python y Git. Una vez hecho esto sigues las instrucciones para copiar el modelo y cargar los requerimientos así:
git clone https://github.com/OpenTalker/SadTalker.git
cd SadTalker
conda create -n sadtalker python=3.8
conda activate sadtalker
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
### Coqui TTS is optional for gradio demo.
### pip install TTS
En Windows debes seguir estos pasos:
- git clone https://github.com/OpenTalker/SadTalker.git
- cd SadTalker
- conda create -n sadtalker python=3.8
- conda activate sadtalker
- pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 –extra-index-url https://download.pytorch.org/whl/cu113
- conda install ffmpeg
- pip install -r requirements.txt
- Coqui TTS is optional for gradio demo.
- pip install TTS
Para instalar el modelo en Mac OS: puedes encontrar un tutorial sobre la instalación de SadTalker en Mac OS aquí .
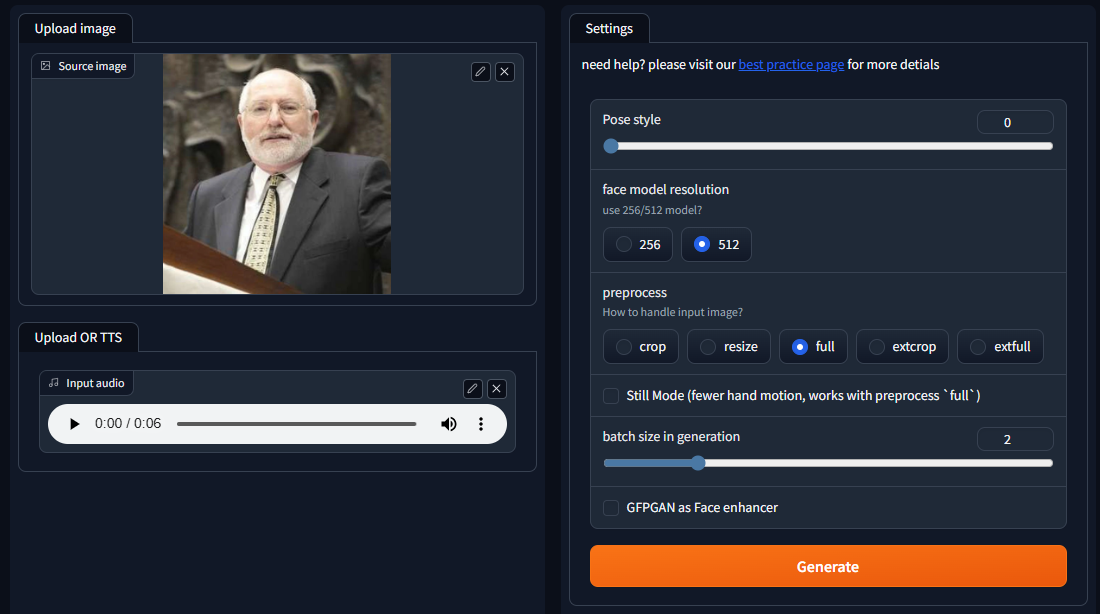
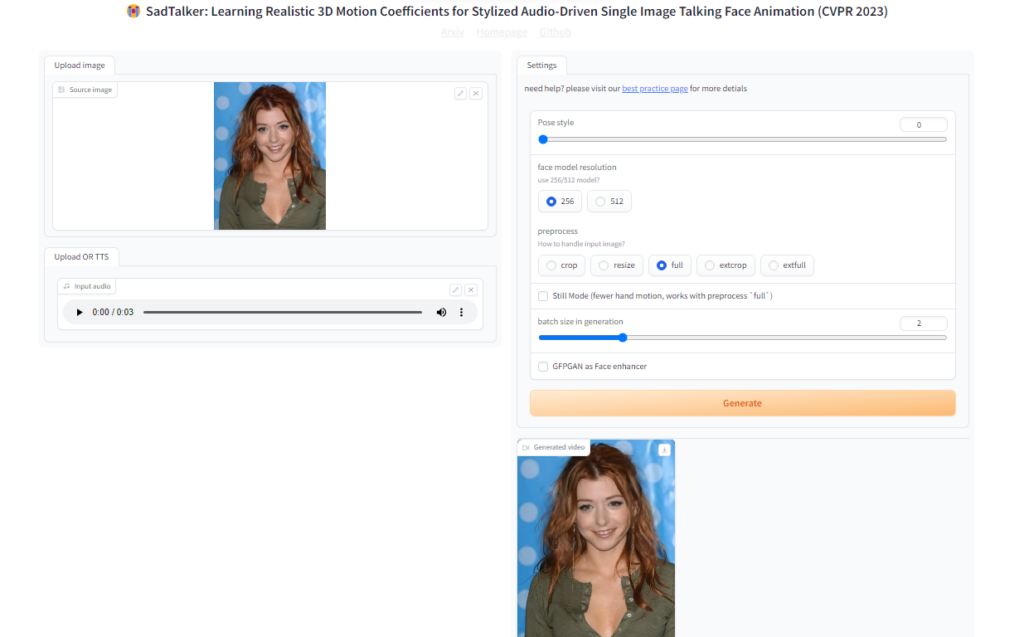
Interfaz de usuario web (UI)
Al instalar el repositorio del modelo de SadTalker puedes ejecutar localmente una instancia gráfica basada en Gradio similar a la que se muestra en el siguiente video de la siguiente forma:
python app_sadtalker.pyTambién puedes iniciar la interface gráfica más fácilmente así:
- Windows: simplemente haga doble clic
webui.bat, los requisitos se instalarán automáticamente. - Linux/Mac OS: ejecute
bash webui.shpara iniciar webui.
Esta interface gráfica envía al modelo un JSON con los parámetros requeridos para la creación del video, con base en los archivos de audio y video, y demás detalles definidos en la misma interface.
Por ejemplo:
{'checkpoint': 'checkpoints\\SadTalker_V0.0.2_256.safetensors', 'dir_of_BFM_fitting': 'src/config', 'audio2pose_yaml_path': 'src/config\\auido2pose.yaml', 'audio2exp_yaml_path': 'src/config\\auido2exp.yaml', 'use_safetensor': True, 'mappingnet_checkpoint': 'checkpoints\\mapping_00109-model.pth.tar', 'facerender_yaml': 'src/config\\facerender_still.yaml'}El video generado se puede recuperar en la carpeta «/results» del mismo directorio donde se instaló el modelo.

SadTalker también utiliza las siguientes bibliotecas de terceros:
- Utilidades faciales : https://github.com/xinntao/facexlib
- Mejora facial : https://github.com/TencentARC/GFPGAN
- Mejora de imagen/vídeo : https://github.com/xinntao/Real-ESRGAN
Te invitamos a explorar gradualmente el mundo del aprendizaje automático, la inteligencia artificial y otras disciplinas afines, fomentando tu participación activa en su aprendizaje y desarrollo. ¡Los resultados son sorprendentes!
Además, te mencionamos finalmente ten en cuenta las consideraciones éticas y legales relacionadas con el uso de imagen y datos de personas, sus consentimientos expresos, y la generación inapropiada de contenido falso.
 Save as PDF
Save as PDF

