
Los embeddings son representaciones numéricas, generalmente en forma de vectores, que capturan la información y relaciones entre datos en un espacio de menor dimensión. En el contexto de inteligencia artificial y machine learning, los embeddings son fundamentales porque permiten transformar datos complejos (como palabras, imágenes o usuarios) en un formato matemático que los modelos pueden procesar de manera eficiente.
¿Propiamente, qué son los embeddings?
- Vectores en un Espacio de Dimensiones Reducidas: Un embedding es esencialmente un vector de números en un espacio de dimensiones más bajas, donde cada número en el vector captura ciertas características o aspectos del dato original.
- Representación Densa: Los embeddings son representaciones densas, lo que significa que cada elemento del vector tiene un valor significativo, a diferencia de las representaciones dispersas (como en el caso de los «one-hot encodings»).
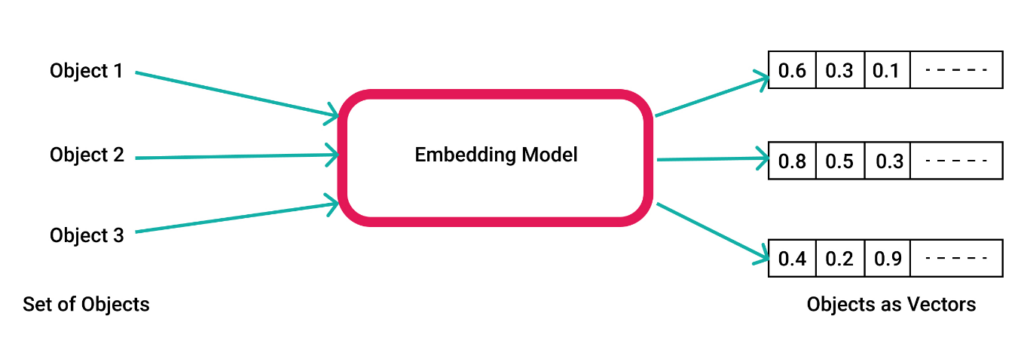
Ejemplos de Embeddings
Word Embeddings:
- En el procesamiento de lenguaje natural (NLP), los embeddings de palabras como Word2Vec, GloVe, y BERT transforman palabras en vectores. Por ejemplo, las palabras «gato» y «perro» pueden tener vectores similares porque tienen significados relacionados.
"gato" -> [0.25, -0.13, 0.89, ...]
"perro" -> [0.28, -0.10, 0.85, ...]Embeddings de Imágenes:
- En visión por computadora, un modelo como una red neuronal convolucional (CNN) puede convertir una imagen en un vector que captura las características visuales más importantes. Por ejemplo, imágenes de «gatos» y «perros» tendrán embeddings cercanos en el espacio vectorial.
Embeddings de Usuarios:
- En sistemas de recomendación, los embeddings pueden representar a usuarios y productos, donde la cercanía entre los vectores indica una mayor probabilidad de que un usuario esté interesado en un producto.
¿Por qué son importantes los embeddings en IA?
- Reducción de Dimensionalidad: Transforman datos complejos en representaciones más manejables y compactas, lo que reduce la dimensionalidad del problema y facilita el procesamiento por parte de modelos de IA.
- Captura de Relaciones Semánticas: Los embeddings son capaces de capturar relaciones semánticas o contextuales entre elementos. Por ejemplo, en NLP, dos palabras que se usan en contextos similares tendrán embeddings cercanos.
- Transferencia de Aprendizaje: Una vez que se ha entrenado un buen modelo de embeddings, estos pueden ser reutilizados en otras tareas relacionadas, ahorrando tiempo y recursos. Por ejemplo, los embeddings preentrenados de palabras pueden ser usados en diferentes aplicaciones de NLP.
- Mejora en la Eficiencia de Búsqueda y Recomendación: En tareas como la búsqueda de información o recomendaciones, los embeddings permiten comparar y recuperar información similar de manera más eficiente que las representaciones tradicionales.
- Versatilidad: Los embeddings pueden ser aplicados a una variedad de dominios, desde texto y audio hasta imágenes y sistemas de recomendación, lo que los convierte en una herramienta fundamental en aplicaciones de IA.
Los embeddings son esenciales en inteligencia artificial porque proporcionan una manera eficiente de representar y manipular datos complejos en espacios de dimensiones reducidas. Al capturar relaciones y patrones subyacentes en los datos, permiten a los modelos de IA realizar tareas como clasificación, búsqueda, recomendación y más con mayor precisión y eficiencia.
Opciones para trabajar con embeddings en PostgreSQL
Es posible trabajar con vectores de embeddings en PostgreSQL utilizando extensiones y herramientas adicionales. Aunque PostgreSQL no tiene soporte nativo para vectores de embeddings, existen varias soluciones que permiten almacenar, indexar y realizar búsquedas eficientes de vectores dentro de una base de datos PostgreSQL.
Extensión pgvector:
pgvectores una extensión popular que agrega soporte para vectores en PostgreSQL. Con esta extensión, puedes almacenar vectores como un tipo de dato y realizar operaciones como búsquedas de similitud utilizando métricas como L2 (distancia euclidiana) o coseno.- Permite realizar consultas como nearest neighbor search (búsqueda del vecino más cercano), lo cual es útil para casos de uso como recomendaciones, búsquedas por similitud, etc.
CREATE EXTENSION vector;
CREATE TABLE items (
id serial PRIMARY KEY,
embedding vector(3) -- vector de 3 dimensiones
);
INSERT INTO items (embedding) VALUES ('[1, 2, 3]');
- PostGIS (con soporte para datos geométricos):
- Si estás trabajando con vectores que tienen un significado espacial, puedes usar PostGIS, una extensión de PostgreSQL para datos geoespaciales. Aunque no está específicamente diseñada para embeddings de AI, puede ser útil en algunos casos donde los vectores representen coordenadas espaciales.
- Integración con herramientas externas:
- Puedes almacenar los vectores en PostgreSQL y realizar búsquedas avanzadas utilizando herramientas externas como FAISS o Annoy para la búsqueda de vecinos más cercanos. PostgreSQL puede actuar como el sistema de almacenamiento principal, mientras que la búsqueda eficiente se maneja externamente.
Ejemplo con pgvector:
SELECT id
FROM items
ORDER BY embedding <-> '[1, 2, 3]'
LIMIT 5;Este ejemplo ordena las filas en función de la similitud de sus vectores con un vector dado.
PostgreSQL puede ser una opción viable para trabajar con vectores de embeddings, especialmente si utilizas la extensión pgvector para manejar y realizar búsquedas eficientes de estos vectores. Esto te permite aprovechar el poder de PostgreSQL mientras trabajas con inteligencia artificial y machine learning.
Para instalar la extensión pgvector en PostgreSQL, sigue los pasos a continuación. Este proceso puede variar ligeramente dependiendo de cómo hayas instalado PostgreSQL (por ejemplo, si usas un paquete de Linux, Docker, etc.), pero los pasos generales son los mismos.
Asegúrate de tener PostgreSQL instalado.
Primero, asegúrate de tener PostgreSQL instalado en tu sistema. Puedes verificar la instalación ejecutando:
psql --versionInstalar pgvector
Opción 1: Instalación desde el repositorio de PostgreSQL
Si estás usando PostgreSQL desde un repositorio que soporta extensiones adicionales, puedes instalar pgvector directamente desde los paquetes proporcionados por PostgreSQL.
Debian/Ubuntu:
sudo apt-get update
sudo apt-get install postgresql-server-dev-13 # Reemplaza 13 por tu versión de PostgreSQLCentOS/RHEL/Rocky/AlmaLinux:
sudo yum install postgresql13-devel # Reemplaza 13 por tu versión de PostgreSQLLuego, clona el repositorio de pgvector y compila la extensión:
git clone https://github.com/pgvector/pgvector.git
cd pgvector
make
sudo make installOpción 2: Instalación desde una imagen de Docker
Si estás utilizando Docker, puedes iniciar un contenedor de PostgreSQL con pgvector preinstalado usando la siguiente imagen:
docker run -d --name pgvector -e POSTGRES_PASSWORD=mysecretpassword -p 5432:5432 ankane/pgvector
Paso 3: Crear la extensión en tu base de datos
Una vez que hayas instalado pgvector, debes habilitar la extensión en la base de datos en la que quieres usarla.
- Conéctate a PostgreSQL:
psql -U postgres -d tu_basedatosCrea la extensión:
CREATE EXTENSION vector;Verifica la instalación
Para verificar que la extensión se instaló correctamente, puedes ejecutar:
\dxDeberías ver vector listado entre las extensiones instaladas.
Paso 5: Usar pgvector
Ahora que la extensión está instalada, puedes comenzar a utilizarla para crear columnas de tipo vector y realizar operaciones de búsqueda.
Ejemplo de uso:
CREATE TABLE items (
id serial PRIMARY KEY,
embedding vector(3) -- vector de 3 dimensiones
);
INSERT INTO items (embedding) VALUES ('[1, 2, 3]');
SELECT * FROM items ORDER BY embedding <-> '[1, 2, 4]' LIMIT 5;
Esto almacenará y realizará una búsqueda por similitud entre vectores usando la distancia euclidiana (la cual está implícita con <->).
La instalación de pgvector es relativamente sencilla, ya sea a través de la compilación manual del código fuente o mediante Docker. Una vez instalada, puedes aprovechar las capacidades avanzadas de búsqueda vectorial en PostgreSQL, lo cual es ideal para aplicaciones que manejan embeddings en inteligencia artificial.
Eiste también la extensión «Postgres Embedding» de LangChain que es una integración que permite realizar búsquedas de similitud vectorial en PostgreSQL utilizando una estructura de índice conocida como Hierarchical Navigable Small Worlds (HNSW). Esta extensión es una alternativa a PGVector, diseñada para mejorar la velocidad de las consultas y escalar aplicaciones de modelos de lenguaje grande (LLM) en PostgreSQL.
Opciones para trabajar con embeddings en MySQL
En MySQL, el soporte para trabajar con vectores de embeddings no es tan avanzado como en PostgreSQL, pero hay algunas maneras de hacerlo, aunque con ciertas limitaciones.
Almacenamiento de Vectores como JSON o Arrays:
- Puedes almacenar los vectores de embeddings como cadenas de texto, JSON o arrays. Sin embargo, esto solo te permite almacenar los datos; la búsqueda por similitud o vecinos cercanos sería bastante ineficiente y requeriría lógica adicional en la aplicación.
CREATE TABLE embeddings (
id INT AUTO_INCREMENT PRIMARY KEY,
embedding JSON
);
INSERT INTO embeddings (embedding) VALUES ('[1.0, 2.0, 3.0]');Consultas Manuales con SQL:
- Una vez almacenados, puedes realizar consultas básicas en SQL para comparar los vectores, pero esto no es escalable ni eficiente para grandes volúmenes de datos. Por ejemplo, podrías calcular la distancia euclidiana manualmente en una consulta SQL, pero esto no es práctico para un gran número de vectores.
SELECT id,
SQRT(POW(embedding->>'$.x' - 1, 2) + POW(embedding->>'$.y' - 2, 2) + POW(embedding->>'$.z' - 3, 2)) AS distance
FROM embeddings
ORDER BY distance
LIMIT 5;SELECT id,
SQRT(POW(embedding->>'$.x' - 1, 2) + POW(embedding->>'$.y' - 2, 2) + POW(embedding->>'$.z' - 3, 2)) AS distance
FROM embeddings
ORDER BY distance
LIMIT 5;- Integración con Herramientas Externas:
- Similar a PostgreSQL, puedes utilizar MySQL como sistema de almacenamiento y realizar búsquedas vectoriales avanzadas utilizando herramientas externas como FAISS o Annoy. MySQL almacenaría los datos, mientras que las búsquedas y cálculos se realizarían en una capa de aplicación externa.
- MySQL HeatWave ML:
- Si estás utilizando MySQL HeatWave en Oracle Cloud, hay capacidades de machine learning integradas en el servicio que pueden ayudar con algunos aspectos de análisis de datos, aunque no está específicamente diseñado como una base de datos vectorial. Sin embargo, puedes aprovechar estas capacidades para modelos y análisis más complejos.
MySQL no está optimizado para funcionar como una base de datos vectorial nativa. Aunque puedes almacenar y manipular vectores, las búsquedas por similitud y otros cálculos relacionados con embeddings serían lentos y poco eficientes sin el uso de herramientas adicionales. Para funcionalidades de vector search más avanzadas, PostgreSQL con pgvector u otras bases de datos especializadas podrían ser más adecuadas.
Vectores en Bases de Datos de Oracle
Para trabajar con vectores de embeddings en Oracle Cloud Infrastructure (OCI), puedes utilizar la Autonomous Database si tu enfoque es más general y quieres aprovechar un servicio completamente administrado. Sin embargo, si necesitas funcionalidades avanzadas específicas para inteligencia artificial y machine learning, como el almacenamiento y búsqueda eficiente de vectores de embeddings, Oracle ha introducido Oracle Database 25c AI (también conocida como 25AI) que incluye funcionalidades especializadas para trabajar con inteligencia artificial, como la gestión y el procesamiento de vectores de embeddings.
- Autonomous Database: Ideal para casos generales donde quieras una solución administrada sin preocuparte por la infraestructura subyacente. Soporta funcionalidades básicas de machine learning y puede trabajar con vectores si implementas las estructuras necesarias.
- Oracle Database 25AI: Recomendado si necesitas capacidades avanzadas para trabajar con inteligencia artificial, como búsqueda vectorial optimizada y otras características específicas para embeddings y modelos de AI.

Tu elección dependerá de los requisitos específicos de tu proyecto y del nivel de control y funcionalidad que necesites.
Para usar embeddings en Autonomous Database en Oracle Cloud Infrastructure (OCI), puedes seguir un enfoque similar al de otras bases de datos, pero aprovechando las capacidades y extensiones específicas de Oracle para optimizar las operaciones.
Paso 1: Configurar la tabla para almacenar embeddings
Primero, necesitas crear una tabla que pueda almacenar los embeddings. Esto se puede hacer utilizando un tipo de dato como BLOB, CLOB o incluso un arreglo de FLOAT si ya sabes la dimensionalidad de los embeddings.
CREATE TABLE product_embeddings (
product_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
product_name VARCHAR2(100),
embedding BLOB -- Puedes cambiar BLOB por CLOB si prefieres almacenar el vector como JSON
);Paso 2: Insertar embeddings en la tabla
Para insertar embeddings en la tabla, puedes convertir tu vector a un formato que Oracle soporte, como una cadena de JSON si usas CLOB, o directamente un binario si usas BLOB.
Ejemplo con JSON:
INSERT INTO product_embeddings (product_name, embedding)
VALUES ('Product A', utl_raw.cast_to_raw('{"embedding": [0.1, 0.2, 0.3]}'));Ejemplo con BLOB:
Si tienes un vector en un formato binario, podrías insertarlo directamente:
DECLARE
l_embedding BLOB := utl_raw.cast_to_raw('0.1,0.2,0.3');
BEGIN
INSERT INTO product_embeddings (product_name, embedding)
VALUES ('Product A', l_embedding);
END;
/Paso 3: Realizar búsquedas utilizando PL/SQL o SQL
Para realizar búsquedas de similitud en embeddings, deberás escribir funciones PL/SQL que calculen la distancia entre los vectores. Por ejemplo, podrías calcular la distancia euclidiana entre el vector de consulta y los vectores almacenados.
Ejemplo de función PL/SQL para calcular distancia euclidiana:
CREATE OR REPLACE FUNCTION euclidean_distance(
vec1 CLOB,
vec2 CLOB
) RETURN NUMBER IS
result NUMBER := 0;
json_vec1 JSON_OBJECT_T := JSON_OBJECT_T.parse(vec1);
json_vec2 JSON_OBJECT_T := JSON_OBJECT_T.parse(vec2);
distance NUMBER;
BEGIN
FOR i IN 1..json_vec1.get_size LOOP
distance := json_vec1.get_number(i) - json_vec2.get_number(i);
result := result + (distance * distance);
END LOOP;
RETURN SQRT(result);
END euclidean_distance;
/Uso de la función en una consulta:
SELECT product_id, product_name, euclidean_distance(embedding, 'embedding_to_compare')
FROM product_embeddings
ORDER BY euclidean_distance(embedding, 'embedding_to_compare')
FETCH FIRST 5 ROWS ONLY;Paso 4: Optimización y uso de capacidades avanzadas
Para mejorar el rendimiento, puedes:
- Crear índices: En columnas que uses frecuentemente en tus búsquedas.
- Utilizar funciones optimizadas: Explora si Oracle ofrece funciones integradas para operaciones numéricas avanzadas en versiones más recientes.
Aunque Autonomous Database de OCI no está específicamente diseñada como una base de datos vectorial, puedes almacenar y manipular embeddings utilizando SQL y PL/SQL, y optimizar las operaciones usando funciones definidas por el usuario. Si trabajas con un gran volumen de datos, es posible que necesites considerar herramientas adicionales o bases de datos especializadas para buscar de manera más eficiente.
En este capítulo se enumeran los siguientes cambios en la Guía del usuario de Oracle Database AI Vector Search para Oracle Database 23a: https://docs.oracle.com/en/database/oracle/oracle-database/23/vecse/whats-new-oracle-ai-vector-search.html
Bases de datos comerciales (web services)
Aparte de las bases de datos mencionadas existen en la web otros servicios comerciales creados especificamente para servir como bases de datos vectoriales. Estas bases de datos están optimizadas para almacenar, indexar y realizar búsquedas eficientes de vectores, lo que las hace ideales para aplicaciones de inteligencia artificial y machine learning, especialmente en tareas como la búsqueda por similitud, recomendaciones, y más.
Principales bases de datos vectoriales comerciales:
- Pinecone
- Descripción: Pinecone es una base de datos vectorial totalmente administrada en la nube, diseñada específicamente para búsquedas de similitud a gran escala. Ofrece una interfaz simple para almacenar, indexar y buscar entre grandes conjuntos de vectores.
- Características:
- Indexación automática: Pinecone se encarga de la indexación de los vectores para optimizar las búsquedas.
- Búsqueda por similitud: Soporta búsquedas basadas en varias métricas de similitud, como la distancia coseno y la distancia euclidiana.
- Escalabilidad: Escala automáticamente para manejar grandes volúmenes de datos.
- Integraciones: Se integra fácilmente con pipelines de machine learning y frameworks como TensorFlow y PyTorch.
- Casos de uso: Sistemas de recomendación, búsqueda semántica, detección de anomalías.
- Weaviate
- Descripción: Weaviate es una base de datos vectorial de código abierto con capacidades adicionales de búsqueda semántica. También está disponible como un servicio en la nube.
- Características:
- Modelo de datos híbrido: Combina datos vectoriales con datos tradicionales en una sola plataforma.
- Búsqueda por similitud: Permite búsquedas vectoriales, incluyendo la búsqueda por contexto y la integración con modelos preentrenados.
- Extensible: Soporte para integrar plugins que amplían la funcionalidad.
- Integración con modelos de lenguaje: Compatible con modelos de lenguaje como GPT para enriquecer las consultas y respuestas.
- Casos de uso: Búsqueda contextual, análisis de documentos, gestión del conocimiento.
- Milvus
- Descripción: Milvus es una base de datos vectorial de código abierto que también está disponible como servicio administrado en la nube. Es altamente optimizada para búsquedas vectoriales a gran escala.
- Características:
- Búsqueda vectorial avanzada: Soporte para diferentes tipos de índices, incluyendo IVF, HNSW y ANNOY.
- Alto rendimiento: Optimizado para manejar billones de vectores con latencia baja.
- Escalabilidad horizontal: Soporta la adición de nodos para mejorar la capacidad y el rendimiento.
- Integraciones: Se integra con herramientas como FAISS, PyTorch y TensorFlow.
- Casos de uso: Recuperación de información multimedia, detección de fraudes, análisis de imágenes.
- Chroma
- Descripción: Chroma es una base de datos vectorial orientada hacia la simplicidad y velocidad en la recuperación de información basada en vectores. Está diseñada para ser utilizada tanto en entornos locales como en la nube.
- Características:
- Similitud semántica: Diseñada para realizar búsquedas rápidas y eficientes utilizando vectores.
- Fácil de usar: Ofrece una API simple que facilita la integración con aplicaciones de machine learning.
- Integración con IA generativa: Compatible con aplicaciones de IA generativa y recuperación aumentada de información (RAG).
- Casos de uso: Chatbots inteligentes, motores de búsqueda personalizados, sistemas de recomendación.
- Qdrant
- Descripción: Qdrant es otra opción de código abierto que también está disponible como servicio SaaS, centrada en la búsqueda y almacenamiento de vectores.
- Características:
- Indexación flexible: Ofrece varios tipos de índices para adaptarse a diferentes casos de uso.
- Optimizado para búsqueda vectorial: Diseñado específicamente para búsquedas rápidas y precisas en grandes conjuntos de datos vectoriales.
- Integraciones: Compatible con frameworks de machine learning y bibliotecas como Hugging Face y ONNX.
- Casos de uso: Recuperación de imágenes, búsqueda de documentos, detección de patrones.
Conclusión
Las bases de datos vectoriales especializadas como Pinecone, Weaviate, Milvus, Chroma, y Qdrant son herramientas poderosas diseñadas para manejar eficientemente la complejidad y las demandas de las aplicaciones de inteligencia artificial moderna. Al estar optimizadas para el almacenamiento y búsqueda de vectores, ofrecen capacidades avanzadas de búsqueda por similitud y escalabilidad, lo que las hace esenciales para proyectos que dependen de la inteligencia artificial y el machine learning.
Para una mejor comprensión de la arquitectira e implementación de información vectorial recomendamos el curso de DeepLearningAI Embedding Models: from Architecture to Implementation.