La frase «one size fits all» en el contexto de las bases de datos relacionales se refiere a la idea de que un solo tipo de sistema de gestión de bases de datos (en este caso, las bases de datos relacionales) podría ser adecuado para todas las aplicaciones y casos de uso. Durante mucho tiempo, las bases de datos relacionales fueron vistas como la solución predeterminada para almacenar y gestionar datos, independientemente de la naturaleza de los datos o de los requisitos específicos de la aplicación.

Origen de «One Size Fits All» en Bases de Datos Relacionales
Las bases de datos relacionales surgieron en los años 70, con el modelo relacional propuesto por Edgar F. Codd y la creación de sistemas de gestión como Oracle, IBM DB2 y Microsoft SQL Server. Este modelo se basa en la organización de datos en tablas con filas y columnas, utilizando SQL (Structured Query Language) como lenguaje estándar para las consultas y la manipulación de datos.
El modelo relacional demostró ser extremadamente eficaz para una amplia gama de aplicaciones empresariales debido a:
- Estructura Rígida: Garantiza la integridad de los datos a través de restricciones como claves primarias y foráneas.
- Consistencia: Ofrece transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) para asegurar la integridad en operaciones complejas.
- Flexibilidad de Consulta: SQL permite realizar consultas complejas y uniones entre múltiples tablas, lo que facilita el análisis de datos relacionados.
Dado su éxito y versatilidad, las bases de datos relacionales se convirtieron en la opción predominante, y la frase «one size fits all» reflejaba la percepción de que este modelo era suficiente para cualquier necesidad de almacenamiento de datos.
Evolución del Entorno de Datos: Aparición de Nuevos Motores de Datos
Con el tiempo, se hizo evidente que el modelo relacional no era ideal para todas las aplicaciones, especialmente con el crecimiento de internet, la explosión de datos no estructurados y el desarrollo de nuevas tecnologías y paradigmas de computación.
- Bases de Datos NoSQL:
- Escalabilidad y Flexibilidad: Las bases de datos NoSQL como MongoDB, Cassandra y Redis surgieron para manejar grandes volúmenes de datos no estructurados o semi-estructurados. A diferencia de las bases de datos relacionales, NoSQL permite la escalabilidad horizontal y ofrece modelos de datos más flexibles (documentos, columnas, grafos, claves-valor).
- Desempeño en Aplicaciones Distribuidas: Se convirtieron en la opción preferida para aplicaciones web, redes sociales y grandes infraestructuras distribuidas debido a su capacidad para manejar cargas de trabajo altamente distribuidas y variadas.
- Bases de Datos de Grafos:
- Relaciones Complejas: Las bases de datos de grafos, como Neo4j, se especializan en modelar y consultar datos donde las relaciones entre entidades son de importancia crítica, como en redes sociales, motores de recomendación y análisis de fraude.
- Bases de Datos Orientadas a Columnas:
- Optimización para Consultas Analíticas: Sistemas como Apache HBase y Google Bigtable se optimizan para consultas analíticas de grandes volúmenes de datos, almacenando los datos por columnas en lugar de filas, lo que mejora el rendimiento en ciertos tipos de consultas.
- Bases de Datos de Vectores:
- Almacenamiento de Datos de Alto Dimensionalidad: Con la evolución de la inteligencia artificial y el aprendizaje profundo, las bases de datos de vectores, como Milvus, están diseñadas para manejar datos de alta dimensionalidad, como embeddings generados por modelos de lenguaje, imágenes o audio. Son clave para aplicaciones que requieren búsquedas de similitud y recuperación de información en grandes conjuntos de datos no estructurados.
Evolución en la Nube
Azure Cosmos DB de Microsoft y Spanner de Google Cloud Platform (GCP) son ejemplos avanzados de cómo las bases de datos han evolucionado para satisfacer las necesidades de las aplicaciones modernas, que requieren alta disponibilidad global, escalabilidad y flexibilidad en el manejo de datos. Ambas bases de datos encajan en esta evolución como soluciones que combinan aspectos de bases de datos relacionales y no relacionales, además de ofrecer características que van más allá de lo que los sistemas tradicionales pueden proporcionar.
Azure Cosmos DB
Azure Cosmos DB es una base de datos multimodelo distribuida globalmente que soporta múltiples modelos de datos y APIs, incluyendo documentos, grafos, columnas anchas, y tablas de claves-valor. Su flexibilidad y características avanzadas la hacen adecuada para una amplia gama de aplicaciones.
- Multimodelo y Multi-API:
- Cosmos DB soporta diferentes modelos de datos, lo que permite a los desarrolladores elegir la API que mejor se adapte a sus necesidades (MongoDB, Cassandra, Gremlin, Table, SQL, entre otros). Esta capacidad multimodelo es clave en la evolución de las bases de datos, ya que permite a las aplicaciones seleccionar el mejor modelo de datos para su caso de uso específico sin cambiar de base de datos.
- Distribución Global y Consistencia Ajustable:
- Cosmos DB ofrece replicación automática en múltiples regiones, lo que asegura alta disponibilidad y baja latencia a nivel global. También permite a los desarrolladores elegir entre cinco modelos de consistencia (fuerte, limitado a sesión, prefijado, eventual), proporcionando un control granular sobre el equilibrio entre consistencia, disponibilidad y latencia.
- Escalabilidad y Rendimiento:
- Cosmos DB está diseñado para escalar horizontalmente con facilidad, lo que permite manejar grandes volúmenes de datos y altas tasas de transacciones de manera eficiente. Su capacidad para particionar automáticamente los datos y distribuir la carga lo convierte en una opción poderosa para aplicaciones que requieren escalabilidad masiva.
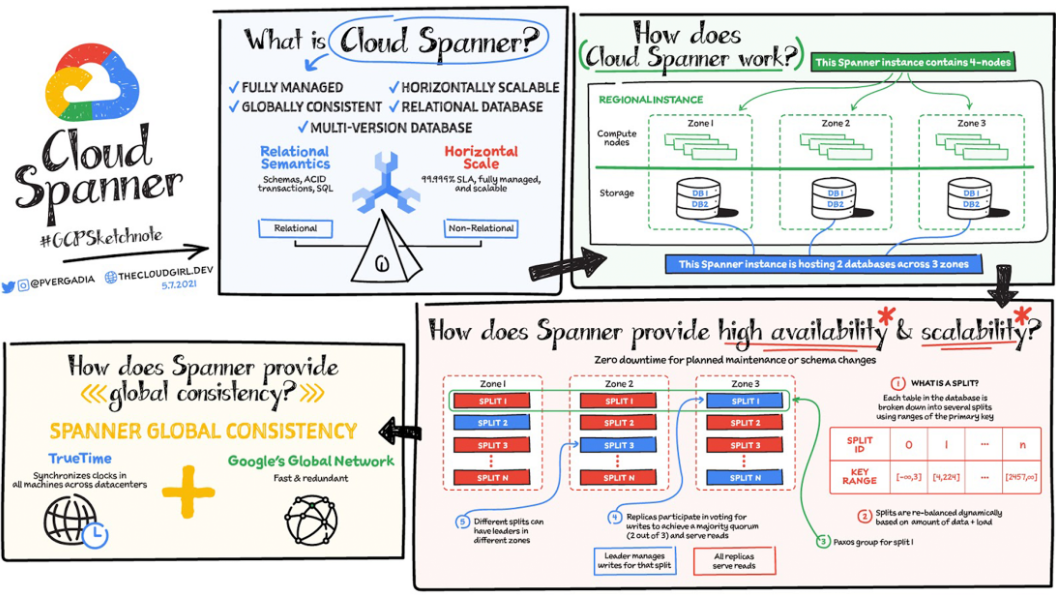
Google Cloud Spanner
Google Cloud Spanner es una base de datos relacional distribuida globalmente que combina las propiedades de las bases de datos relacionales (como el soporte para transacciones ACID y el uso de SQL) con las ventajas de la escalabilidad horizontal y la replicación global típica de las bases de datos no relacionales.
- Transacciones ACID a Escala Global:
- Spanner es única en su capacidad para ofrecer transacciones ACID consistentes a través de múltiples regiones geográficas, algo que históricamente ha sido difícil de lograr en sistemas distribuidos a gran escala. Esto lo hace ideal para aplicaciones críticas que requieren tanto consistencia estricta como alta disponibilidad global.
- SQL Relacional y Escalabilidad Horizontal:
- Spanner soporta SQL para consultas y gestión de datos, permitiendo a las aplicaciones utilizar un modelo relacional familiar, mientras se beneficia de la escalabilidad horizontal y la replicación transparente en todo el mundo. Esto lo diferencia de las bases de datos NoSQL, que a menudo sacrifican la consistencia y las transacciones complejas por la escalabilidad.
- Sincronización de Reloj Global (TrueTime):
- Una de las innovaciones clave de Spanner es su uso del sistema de sincronización de reloj global TrueTime, que permite garantizar la consistencia de las transacciones distribuidas a nivel global. TrueTime ayuda a Spanner a superar los desafíos de la sincronización de relojes en sistemas distribuidos, permitiendo a los desarrolladores escribir aplicaciones que dependen de la precisión temporal a escala global.

Encaje en la Evolución del Entorno de Datos
Tanto Azure Cosmos DB como Google Cloud Spanner son ejemplos de cómo las bases de datos han evolucionado para superar las limitaciones del modelo relacional tradicional, ofreciendo soluciones que combinan lo mejor de ambos mundos (relacional y no relacional) en términos de escalabilidad, flexibilidad, y disponibilidad global.
- Soluciones Híbridas: Ambos sistemas representan una evolución hacia soluciones híbridas que combinan aspectos de bases de datos relacionales (transacciones ACID, SQL) con la capacidad de manejar grandes volúmenes de datos distribuidos a nivel global, algo más típico de las bases de datos NoSQL.
- Enfoque en la Disponibilidad Global: La replicación global y la baja latencia son características clave, lo que refleja la necesidad moderna de aplicaciones que funcionen de manera eficiente en una infraestructura global distribuida.
- Consistencia y Escalabilidad a Demanda: Ambos servicios permiten ajustar la consistencia y escalar horizontalmente, proporcionando a las aplicaciones la capacidad de adaptarse a diferentes cargas de trabajo y requisitos de datos.
En resumen, Azure Cosmos DB y Google Cloud Spanner encajan en la evolución del entorno de datos como bases de datos distribuidas de nueva generación, diseñadas para satisfacer las demandas de aplicaciones modernas que requieren una combinación de flexibilidad en el manejo de datos, consistencia, y escalabilidad global.
Conclusión: Del «One Size Fits All» a la Especialización
El paradigma «one size fits all» ha dado paso a un entorno de datos mucho más diversificado y especializado. Hoy en día, las organizaciones seleccionan motores de bases de datos basados en las características de sus aplicaciones y los tipos de datos que manejan. La evolución del entorno de datos ha llevado a la adopción de una arquitectura más heterogénea, donde diferentes motores de datos coexisten para satisfacer necesidades específicas, desde transacciones financieras hasta análisis de redes sociales o inteligencia artificial.