En el acelerado mundo de la ciencia de datos, a menudo caemos en rutinas que, aunque eficientes a primera vista, nos privan de una comprensión profunda de nuestros activos más valiosos: los datos. Una de estas rutinas es relegar la visualización a la fase final del proyecto, tratándola como un «adorno» para presentar resultados. Pero, ¿y si te dijera que este enfoque podría estar limitando tu potencial y la robustez de tus modelos?
Como se ha señalado, la frase «Necesitas entender la naturaleza de tus datos, y la visualización es un método clave para lograrlo» resuena con una verdad fundamental. Exploremos por qué la visualización no es solo para el final, sino una herramienta indispensable desde el inicio y a lo largo de todo el ciclo de vida de un proyecto de ciencia de datos.
El Enfoque Tradicional: ¿Un Camino Menos Eficiente?
Es común observar este patrón: el Análisis Exploratorio de Datos (EDA) se realiza de manera «rápida». Se utilizan funciones como df.head(), df.describe(), y se cuentan valores para obtener estadísticas generales, revisando tablas, filas y columnas. Luego, el equipo se sumerge en la limpieza, transformación y entrenamiento de modelos. Solo al final, cuando se necesita un reporte, se generan gráficos «bonitos».
Este método, aunque parece lógico, ignora una verdad poderosa: nuestro cerebro procesa y comprende patrones visuales de manera mucho más eficiente que los numéricos. Una tabla con 50 columnas y 10,000 filas apenas nos revela relaciones, tendencias, valores atípicos o clústeres ocultos. En contraste, una visualización simple puede desvelar en segundos lo que docenas de líneas de estadísticas no logran comunicar claramente.
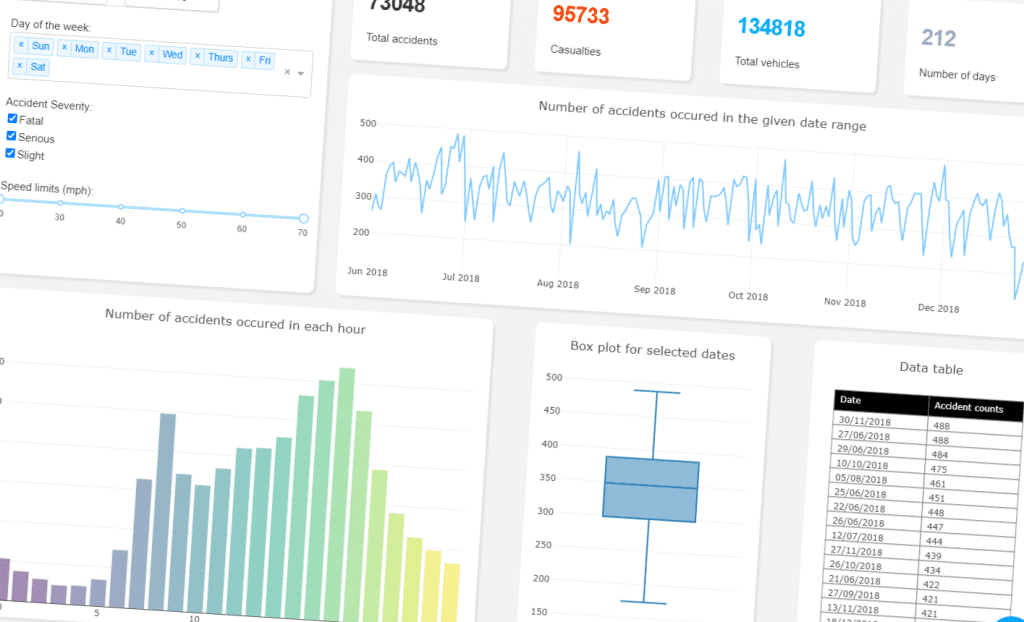
La Propuesta: Visualización al Inicio para una Inducción más Potente
La clave es invertir el orden de trabajo, moviendo las visualizaciones al inicio del análisis. Esto favorece un enfoque más inductivo:
- Primero observamos el comportamiento general de los datos de manera intuitiva.
- Luego deducimos hipótesis y decidimos transformaciones basadas en lo que hemos visto.
Este cambio no solo ahorra tiempo al detectar errores o rarezas tempranamente, sino que también contribuye a la creación de modelos más sólidos, ya que se construyen sobre datos que se comprenden mejor.
Piensa en el poder de estas visualizaciones iniciales:
- Un histograma te revela el sesgo o la presencia de valores extremos en una variable.
- Un scatter plot muestra rápidamente si hay correlaciones o clústeres naturales.
- Un boxplot indica si la mediana y la dispersión son razonables, o si existen valores aberrantes.
- Un heatmap de correlación puede guiarte sobre qué variables podrían ser redundantes.
Recomendación Práctica: Integra la Visualización en tu Pipeline de EDA
Para implementar este enfoque, considera las siguientes acciones:
• Incluye un bloque de visualización inicial en tu pipeline de EDA con histogramas, pairplots, boxplots y gráficos de correlación.
• Utiliza librerías potentes como Matplotlib, Seaborn o Plotly para generar estos insights de forma rápida.
• Documenta tus observaciones: Por ejemplo, si una «distribución sesgada» sugiere «aplicar transformación logarítmica», o si «muchos nulos» requieren «revisar la imputación».
Visualización: El Hilo Conductor en Todas las Etapas del Ciclo de Vida de Data Science
La visualización no es un paso aislado; es un elemento que puede y debe estar presente en todas las etapas del ciclo de vida de un proyecto de data science, refinando la toma de decisiones en cada paso.
Visualización como parte integral del ciclo de ciencia de datos:
1. Carga de Datos (Ingesta)
◦ Objetivo: Obtener una visión general de la estructura y calidad de los datos.
◦ Gráficos útiles: Barras apiladas para nulos, histogramas rápidos para variables numéricas (valores extremos), countplots para variables categóricas (balance de clases).
◦ Beneficio: Detección temprana de problemas (faltantes, duplicados, escalas absurdas).
2. 🧹 Limpieza y Transformación
◦ Objetivo: Verificar que las transformaciones producen el efecto esperado.
◦ Gráficos útiles: Comparaciones lado a lado (antes/después) con histogramas o boxplots; heatmaps de correlaciones antes y después de escalar/normalizar para evaluar el impacto en las relaciones entre variables; distribuciones de variables derivadas.
◦ Beneficio: Reduce errores de ingeniería de características, valida supuestos.

3. 🔍 Exploración Avanzada y Feature Engineering
◦ Objetivo: Encontrar relaciones no triviales y construir nuevas características.
◦ Gráficos útiles: Pairplots o scatter matrices para observar tendencias entre múltiples variables; gráficos de densidad o violin plots para detectar patrones en subgrupos; visualizaciones de importancia de variables (SHAP, Permutation Importance).
◦ Beneficio: Selección de características más informada, modelos menos sobreajustados.
4. 🧠 Modelado y Evaluación
◦ Objetivo: Entender el desempeño del modelo más allá de una métrica numérica.
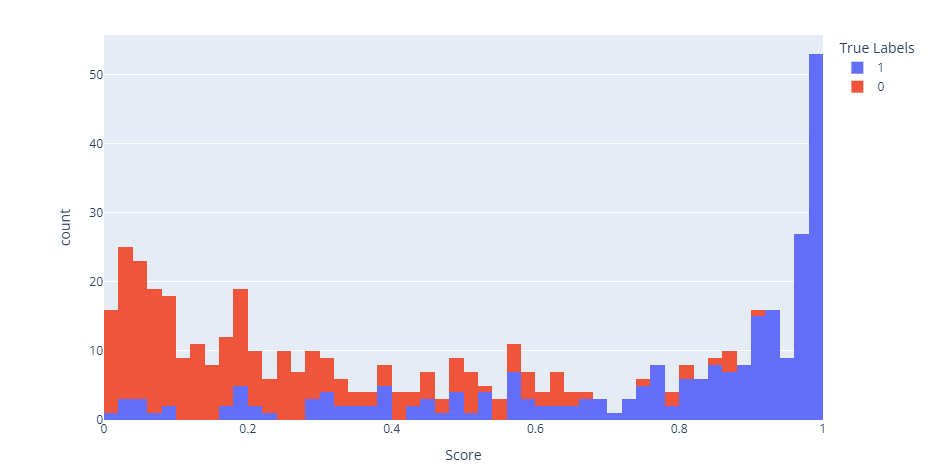
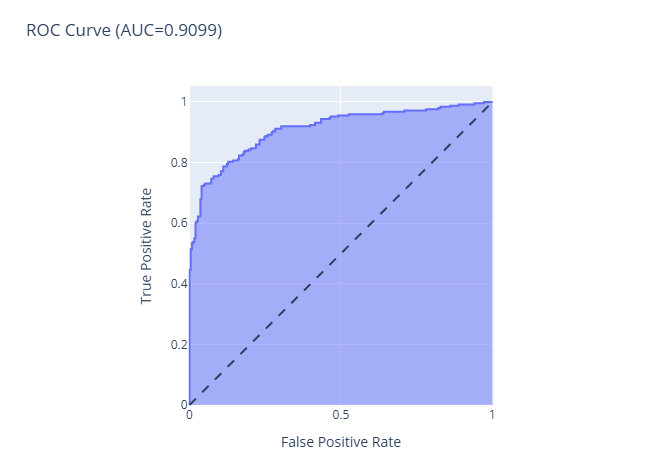
◦ Gráficos útiles: Matriz de confusión (para clasificación); curvas ROC y Precision-Recall; gráficos de error residual (para regresión).
◦ Beneficio: Comprender por qué el modelo funciona o falla y qué mejorar.
5. 📊 Comunicación y Despliegue
◦ Objetivo: Contar una historia clara y convincente a los stakeholders.
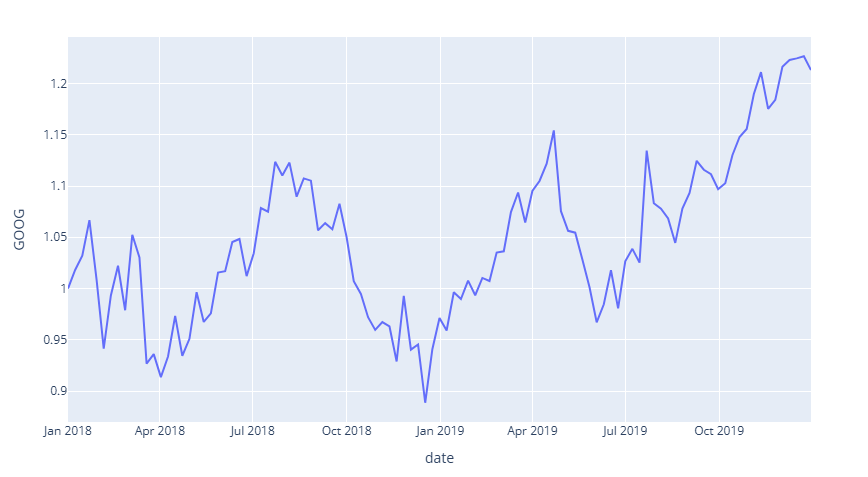
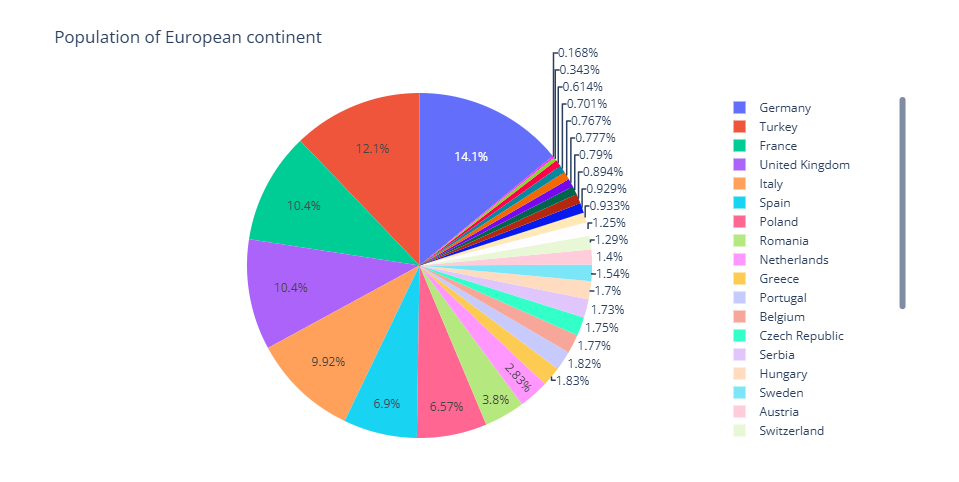
◦ Gráficos útiles: Dashboards interactivos (Plotly Dash, Oracle ADS UI); series de tiempo, mapas geográficos, KPI visuales.
◦ Beneficio: Convencer con evidencia visual y facilitar la toma de decisiones basada en datos.
Conclusión: Una Mentalidad de Data Scientist Experimentado
Esta observación, y la de muchos científicos de datos experimentados, es sumamente potente porque plantea un cambio que es más de mentalidad que de herramientas: visualizar no solo al final, sino en cada etapa, para guiar el razonamiento y la toma de decisiones. Esta iteración continua entre observación, hipótesis, ajuste y verificación es precisamente lo que distingue a un data scientist experimentado de uno junior.
Incorpora la visualización como una brújula en tu viaje de datos, y verás cómo tu comprensión, tus modelos y tus resultados alcanzan un nuevo nivel de excelencia.
Recurso recomendado: Plotly Open Source Graphing Library for Python
 Save as PDF
Save as PDF

