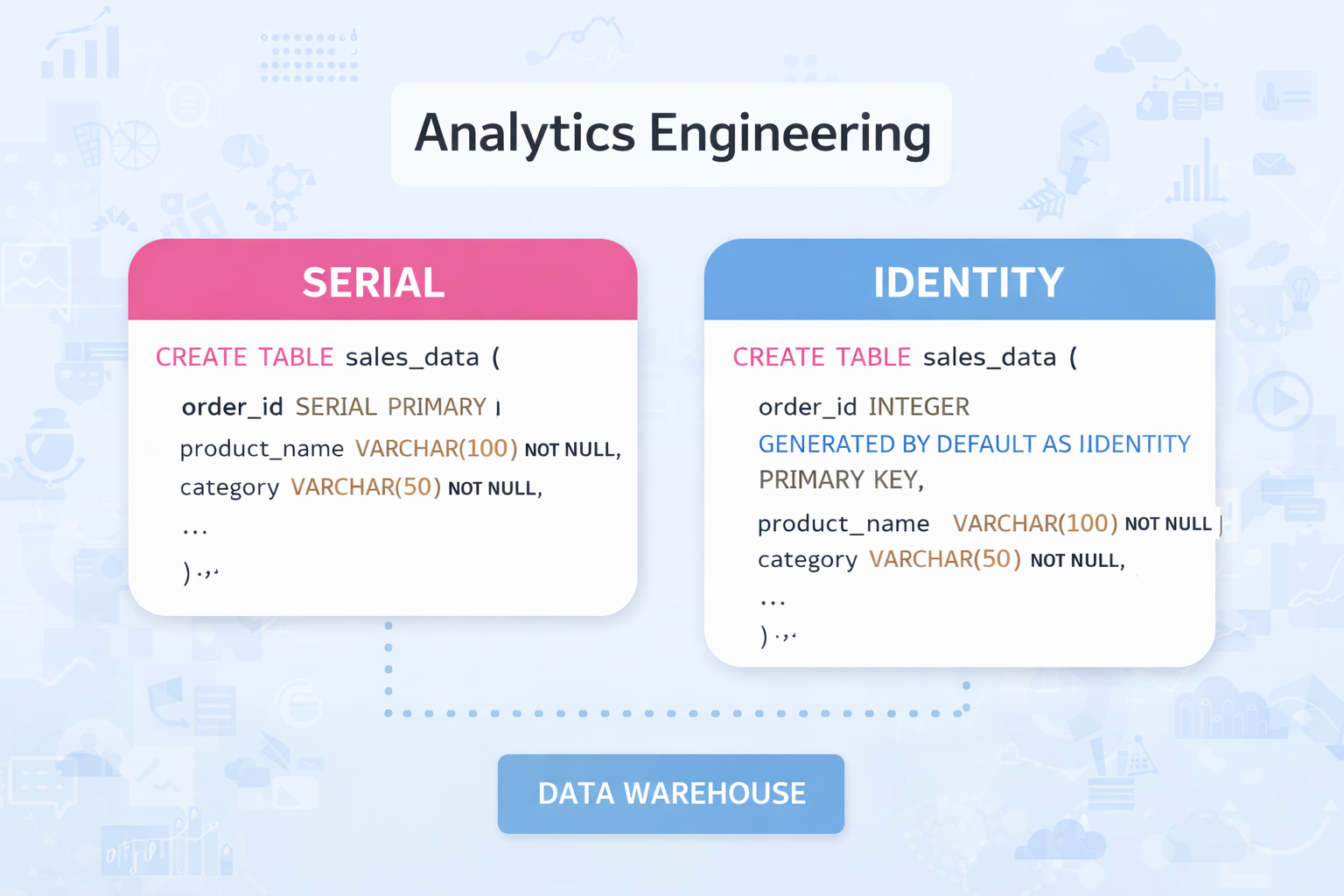
Durante años, quienes trabajamos con PostgreSQL hemos usado SERIAL casi de forma automática para definir claves primarias autoincrementales. Sin embargo, desde la versión 10 existe una alternativa estándar: GENERATED AS IDENTITY.
La diferencia no es solo sintáctica. Refleja la evolución histórica de los motores de bases de datos, la estandarización del SQL y los cambios en la arquitectura moderna de datos, especialmente en entornos de Analytics Engineering.
En este artículo analizamos cuatro dimensiones clave del tema.
1. La tradición en PostgreSQL: SERIAL sigue funcionando (incluso en v18)
SERIAL es una extensión propia de PostgreSQL. No es un tipo real, sino azúcar sintáctico que internamente:
- Crea una secuencia.
- Define una columna
INTEGER. - Asigna como valor por defecto
nextval()de esa secuencia.
Ejemplo clásico:
CREATE TABLE sales_data (
order_id SERIAL PRIMARY KEY,
product_name VARCHAR(100) NOT NULL,
category VARCHAR(50) NOT NULL,
quantity INT NOT NULL CHECK (quantity >= 0),
unit_price NUMERIC(10,2) NOT NULL CHECK (unit_price >= 0),
order_date DATE NOT NULL
);Internamente, PostgreSQL hace algo equivalente a:
CREATE SEQUENCE sales_data_order_id_seq;CREATE TABLE sales_data (
order_id INTEGER NOT NULL
DEFAULT nextval('sales_data_order_id_seq'),
product_name VARCHAR(100) NOT NULL,
category VARCHAR(50) NOT NULL,
quantity INT NOT NULL CHECK (quantity >= 0),
unit_price NUMERIC(10,2) NOT NULL CHECK (unit_price >= 0),
order_date DATE NOT NULL
);ALTER SEQUENCE sales_data_order_id_seq
OWNED BY sales_data.order_id;
SERIAL sigue siendo perfectamente válido y estable. Muchos proyectos productivos lo usan sin problema. Sin embargo, no forma parte del estándar SQL.
2. SQL estándar moderno: GENERATED AS IDENTITY
El estándar SQL formalizó el concepto de columnas identidad mediante:
GENERATED { ALWAYS | BY DEFAULT } AS IDENTITYDesde PostgreSQL 10, esta sintaxis está disponible y es la forma recomendada en proyectos nuevos.
Ejemplo equivalente al anterior:
CREATE TABLE sales_data (
order_id INTEGER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
product_name VARCHAR(100) NOT NULL,
category VARCHAR(50) NOT NULL,
quantity INT NOT NULL CHECK (quantity >= 0),
unit_price NUMERIC(10,2) NOT NULL CHECK (unit_price >= 0),
order_date DATE NOT NULL
);Diferencias clave:
ALWAYS vs BY DEFAULT
order_id INTEGER GENERATED ALWAYS AS IDENTITY- La base de datos siempre genera el valor.
- Insertar manualmente un ID produce error (salvo usando
OVERRIDING SYSTEM VALUE).
order_id INTEGER GENERATED BY DEFAULT AS IDENTITY- La base genera el valor si no se proporciona uno.
- Permite insertar manualmente valores explícitos.

Personalización de la secuencia
Con IDENTITY se pueden definir parámetros directamente en la columna:
CREATE TABLE example_identity (
id INTEGER GENERATED BY DEFAULT AS IDENTITY
(START WITH 1000 INCREMENT BY 10),
description TEXT
);Esto mejora claridad semántica y portabilidad. Aunque PostgreSQL sigue usando secuencias internamente, la relación es formal y gestionada como propiedad de la columna.
3. Evolución histórica: el autoincrement nunca fue unificado
Durante décadas, cada motor resolvió el problema del autoincremento a su manera:
- MySQL:
AUTO_INCREMENT - SQL Server:
IDENTITY - Oracle: secuencias (y luego identidad)
- PostgreSQL:
SERIAL - SQLite:
INTEGER PRIMARY KEY
No existía una convención estándar común. La formalización de GENERATED AS IDENTITY fue un intento de unificar semántica y metadatos.
Por eso muchos tutoriales introductorios aún usan SERIAL:
- Es más corto.
- Es familiar.
- Funciona sin inconvenientes.
- Reduce complejidad conceptual en cursos básicos.
En contextos pedagógicos iniciales, el foco suele estar en aprender SQL o modelado, no en discutir estándares y portabilidad.
4. Analytics Engineering y el rol real de las claves surrogate
En entornos modernos de Analytics Engineering (por ejemplo, trabajando con warehouses y herramientas tipo dbt, DuckDB), el rol de las claves cambia.
En muchos casos:
- El ID ya viene de la fuente (ERP, CRM, aplicación transaccional).
- El warehouse no genera el identificador.
- Las claves surrogate se generan mediante funciones hash.
Ejemplo típico en modelos analíticos:
SELECT
md5(concat(customer_id, '-', order_date)) AS surrogate_key,
customer_id,
order_date,
total_amount
FROM staging_orders;Aquí no se usa autoincremento. Se genera una clave determinística basada en atributos del negocio.
En modelado dimensional (por ejemplo, dimensiones tipo SCD), también es frecuente generar claves surrogate en procesos intermedios y no depender de secuencias autoincrementales del motor.
Advertencia saludable: MD5 no es seguro criptográficamente hoy en día. Pero para surrogate keys analíticas, no buscamos seguridad criptográfica; buscamos baja probabilidad de colisión y determinismo. Para analytics es suficiente.
En este contexto, la discusión SERIAL vs IDENTITY pierde protagonismo. La generación del identificador ya no es responsabilidad directa del warehouse.
5. SQL estándar y migraciones entre motores: la diferencia práctica
Usar SQL estándar no es una obsesión académica. Es una decisión que puede simplificar o complicar una migración futura.
Cuando se define una columna con:
order_id SERIAL PRIMARY KEYestamos usando una extensión específica de PostgreSQL. Si mañana el proyecto necesita migrar hacia otro motor (por ejemplo, SQL Server, Oracle o incluso un entorno híbrido multi-engine), ese código no será directamente compatible.
En cambio, con sintaxis estándar:
order_id INTEGER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEYla semántica es reconocible en motores que implementan el estándar moderno. Aunque cada sistema tenga matices internos, la intención es clara y portable.
¿Qué implica esto en la práctica?
Supongamos que una empresa:
- Comienza con PostgreSQL.
- Crece.
- Decide mover su warehouse o parte del sistema transaccional a otro motor por razones de rendimiento, licenciamiento o integración.
Si el esquema fue diseñado usando extensiones específicas (SERIAL, tipos particulares no estándar, funciones propietarias), la migración requerirá:
- Refactorización del DDL.
- Ajustes manuales en secuencias.
- Revisión de metadatos.
- Más pruebas.
En cambio, cuando el diseño se apoya en estándar SQL, el proceso es mucho más directo. El esfuerzo de migración se concentra en diferencias reales de comportamiento, no en detalles sintácticos heredados.
Un ejemplo comparativo
PostgreSQL específico:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username TEXT NOT NULL
);Más portable:
CREATE TABLE users (
id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
username TEXT NOT NULL
);El segundo expresa la intención de forma estándar. El primero depende del dialecto.
Las decisiones pequeñas en el DDL pueden parecer irrelevantes al inicio del proyecto. Pero el diseño de esquemas es infraestructura conceptual.
Elegir entre SERIAL e IDENTITY no es solo una cuestión de moda o estilo. Es una decisión sobre:
- Portabilidad futura.
- Claridad semántica.
- Alineación con el estándar.
- Evolución tecnológica del proyecto.
En sistemas que nacen pequeños pero aspiran a escalar o integrarse con múltiples motores, el estándar deja de ser una formalidad y se convierte en una ventaja estratégica.
Podemos sintetizar el panorama en cuatro ideas:
SERIALes tradición en PostgreSQL y sigue funcionando perfectamente.GENERATED AS IDENTITYes la forma estándar, más portable y semánticamente limpia.- La diferencia refleja la evolución histórica de los motores de bases de datos.
- En Analytics Engineering moderno, muchas veces ni siquiera se usan columnas identidad clásicas.
Para proyectos nuevos orientados a buenas prácticas y posible portabilidad, IDENTITY es la opción más alineada con el estándar SQL. Para aprendizaje básico o proyectos internos, SERIAL continúa siendo una alternativa válida y estable.
Entender estas capas —histórica, técnica
 Save as PDF
Save as PDF

