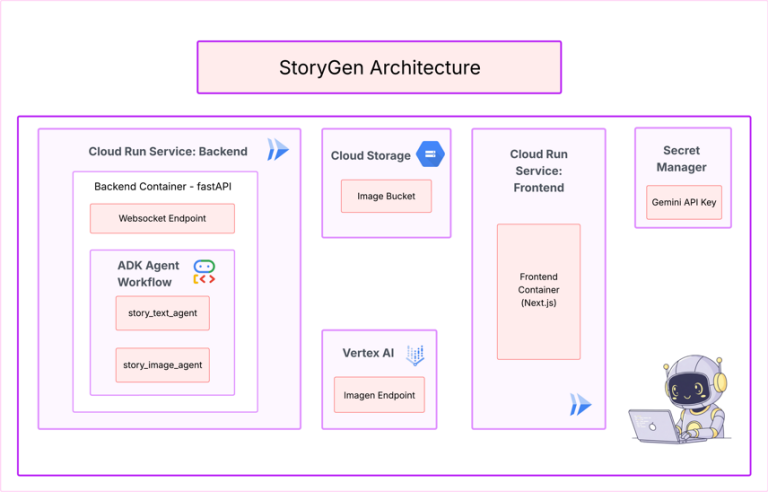
En este ejercicio leeremos una biblioteca de iTunes en valores separados por comas (CSV) y produciremos tablas correctamente normalizadas como se especifica a continuación.

Haremos algunas cosas de manera diferente en esta tarea. No usaremos una tabla «en bruto» separada, solo usaremos declaraciones ALTER TABLE para eliminar columnas después de que no las necesitemos (es decir, las convertimos en claves foráneas).
Utilizaremos este CSV que contiene la información de las pistas musicales. No usaremos una tabla «en bruto» separada, solo usaremos declaraciones ALTER TABLE para eliminar columnas después de que no las necesitemos (es decir, las convertimos en claves foráneas).
Esta vez construiremos una relación de muchos a muchos usando una tabla de junction/through/join entre pistas y artistas.
El script para construir las tablas que vamos a utilizar:
CREATE TABLE album (
id SERIAL,
title VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
);
CREATE TABLE track (
id SERIAL,
title TEXT,
artist TEXT,
album TEXT,
album_id INTEGER REFERENCES album(id) ON DELETE CASCADE,
count INTEGER,
rating INTEGER,
len INTEGER,
PRIMARY KEY(id)
);
CREATE TABLE artist (
id SERIAL,
name VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
);
CREATE TABLE tracktoartist (
id SERIAL,
track VARCHAR(128),
track_id INTEGER REFERENCES track(id) ON DELETE CASCADE,
artist VARCHAR(128),
artist_id INTEGER REFERENCES artist(id) ON DELETE CASCADE,
Luego procedemos a copiar los datos contenidos en el CSV a la tabla track (recuerda ingresar a la línea de comandos con la instrucción psql):
\copy track(title,artist,album,count,rating,len) FROM 'library.csv' WITH DELIMITER ',' CSV;Seguidamente actualizamos las tablas album y artist con los datos únicos (SELECT DISTINCT) de los campos album y artists de la tabla track. De igual forma los campos track y artist de la tabla tracktoartist desde los campos title y artist de la tabla track.
INSERT INTO album (title) SELECT DISTINCT album FROM track;
INSERT INTO artist (name) SELECT DISTINCT artist FROM track;
UPDATE track SET album_id = (SELECT album.id FROM album WHERE album.title = track.album);
INSERT INTO tracktoartist (track, artist) SELECT DISTINCT title, artist FROM track; Una vez hecho esto actualizamos los campos track_id y artist_id de la tabla tracktoartist con los respectivos «id’s» de las tablas track y artist.
UPDATE tracktoartist SET track_id = (SELECT track.id FROM track WHERE track.title = tracktoartist.tracK);
UPDATE tracktoartist SET artist_id = (SELECT artist.id FROM artist WHERE artist.name = tracktoartist.artist);De esta forma habremos normalizado esta información de Pistas Musicales creando las respectivas relaciones de modo que ahora podemos ejecutar una consulkat como la siguiente:
SELECT track.title, album.title, artist.name
FROM track
JOIN album ON track.album_id = album.id
JOIN tracktoartist ON track.id = tracktoartist.track_id
JOIN artist ON tracktoartist.artist_id = artist.id
LIMIT 3;Obtendremos un resultado como el siguiente:

Para finalizar podemos eliminar los datos que nos sobran, las columnas album y artist de la tabla track y los campos track y artist de la tabla tracktoartist, a traves de la instrucción ALTER TABLE … DROP COLUMN.
 Save as PDF
Save as PDF